
Introduction
Parents greatly value their children's education, and heavily weigh the quality of the local schools when relocating. Aside from school rankings in standardized test scores, such as the SAT, school quality was once only spread through word of mouth. However, these days, in addition to these traditional metrics, sites such as GreatSchools.org also aggregate online school user reviews and ratings. How do these reviews and ratings relate to standard measures of school quality? Are they useful for parents in choosing a town to move to?
To answer these questions, I compared the Great Schools ratings to more traditional school metrics such as graduation rate, dropout rate, average SAT score, and percent of students college-bound. I also examined the reviews for missing ratings, and then used natural language processing to determine if the textual content of the reviews could be used to impute a proxy rating for the school on behalf of the reviewer. I chose high schools within a 60 mile radius of Maplewood, NJ in order to limit the data set while also maximizing the socioeconomic spectrum across which I was analyzing the data.
Although the traditional measures of school metrics were available from the NJ government web site, I had to use a Python program called Scrapy to retrieve the user reviews and ratings off of the GreatSchools.org website and manually match up the school names between the two data sets. I ended with the below metrics:
| NJ.gov | Greatschools.org |
|---|---|
| SAT Score | GS.org school Rating (“Expert Rating”) |
| Dropout Rate | User Ratings (”sentiment”) |
| Graduation Rate | User Reviews |
| % College bound |
Part 1: Uniformly Great?
To set a baseline, I examined the relationship between schools' GreatSchools.org rating and their traditional metrics. It's clear that GreatSchools.org uses traditional metrics to guide its rating. You can see that all the metrics trend in an intuitive direction with the GreatSchools.org rating.
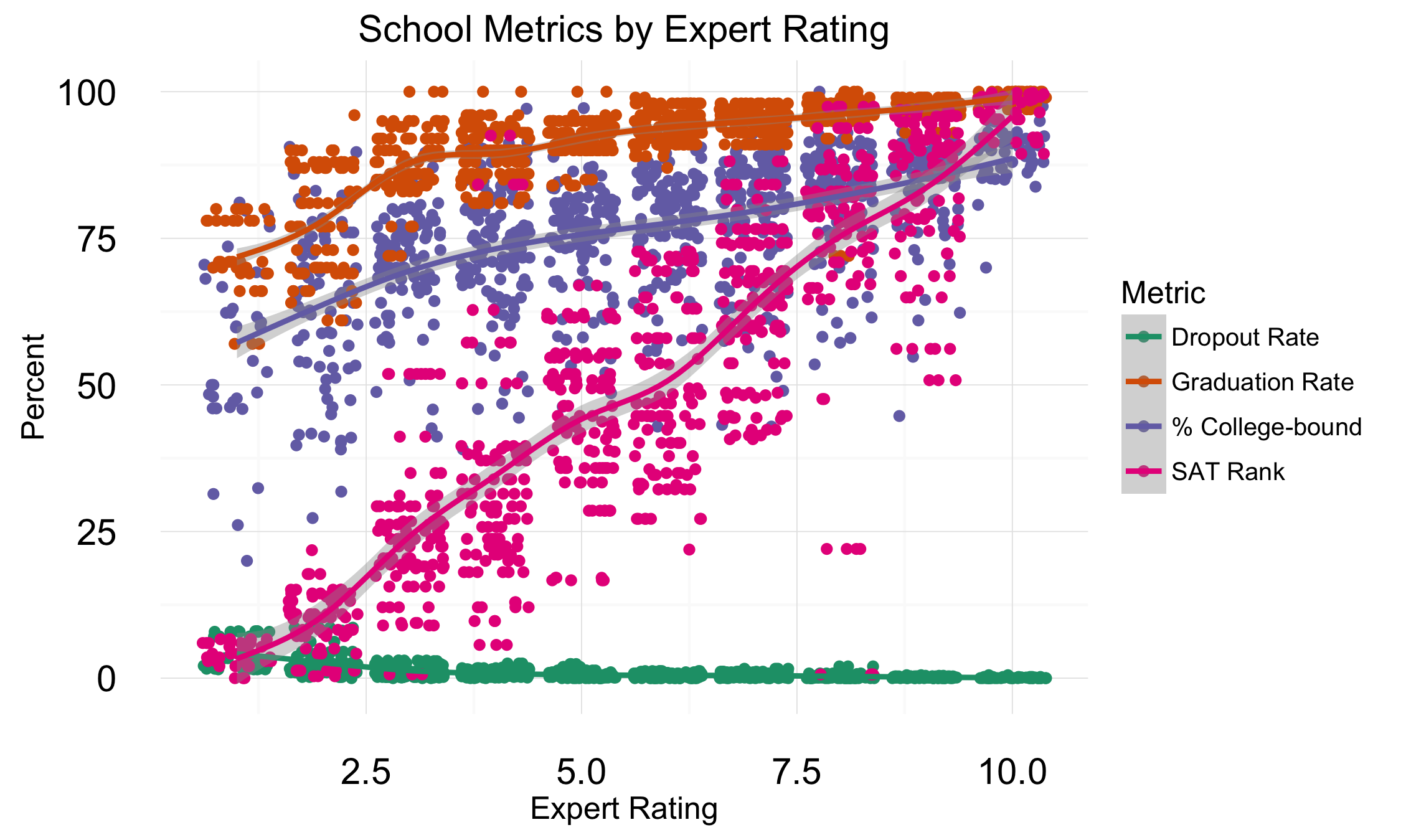
In contrast, the user ratings did not reflect the same trend. There is no statistical correlation between the traditional metrics and the user ratings. This could imply one of two things: first, there may be no information in the user ratings at all aside from an individual's subjective reality. Alternatively, the user rating may be measuring interesting qualities of a school that are orthogonal to traditional metrics.
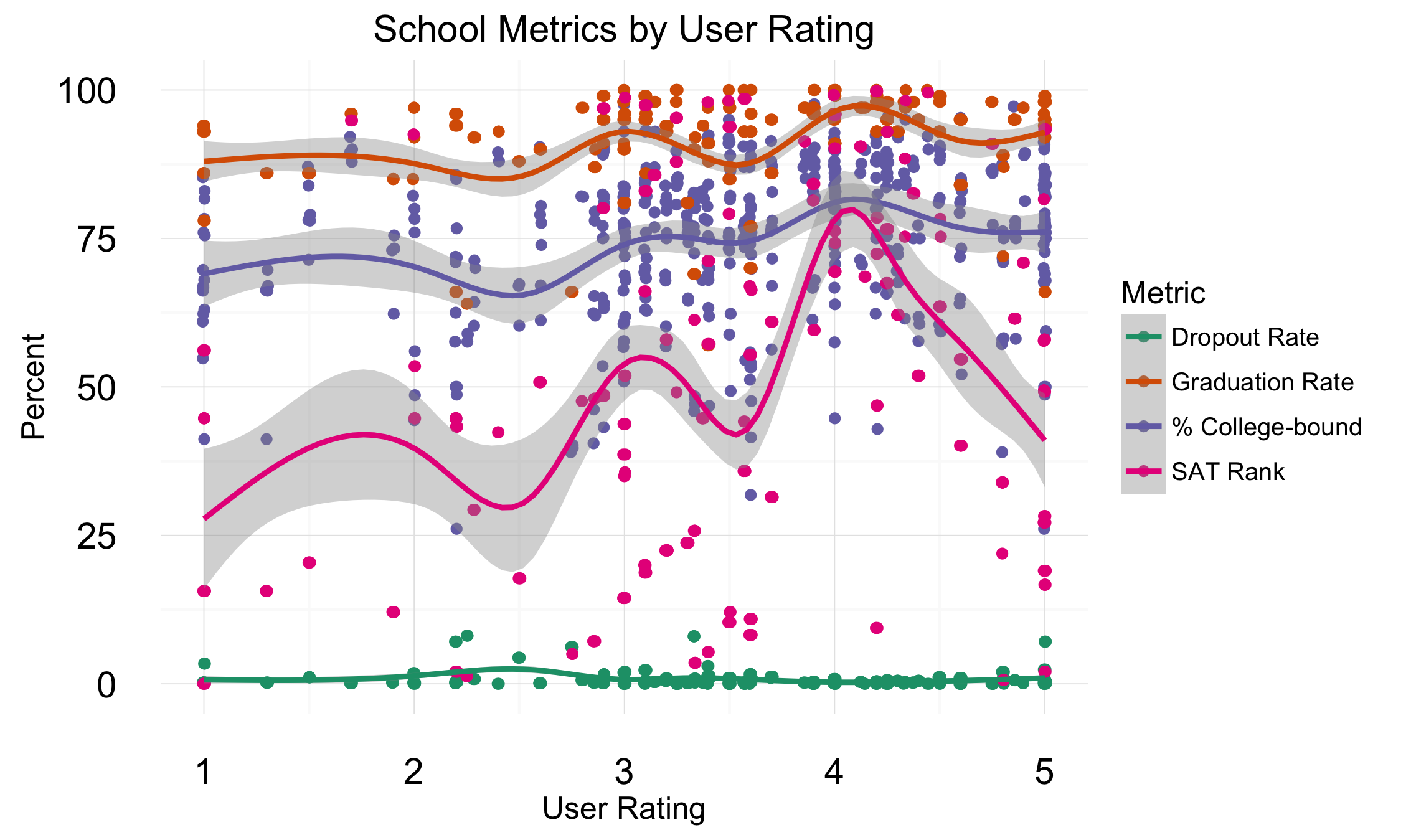
Below we can see both the user rating ("sentiment") and the GreatSchools.org rating ("expert rating") against SAT scores. It's clear that there is, indeed, a large range of sentiments for schools with top SAT scores. However, there are not many high-scoring schools with low sentiment rating. Also, there are schools with absolutely dismal SAT scores that have high sentiment ratings. This latter group is interesting, and I'd like to examine them more closely in the future. Could it be that these schools excel in dimensions of performance not related to traditional outcomes? Unfortunately, this would have to wait because I identified a potential missingness issued related to this variable, which I address in part 2.
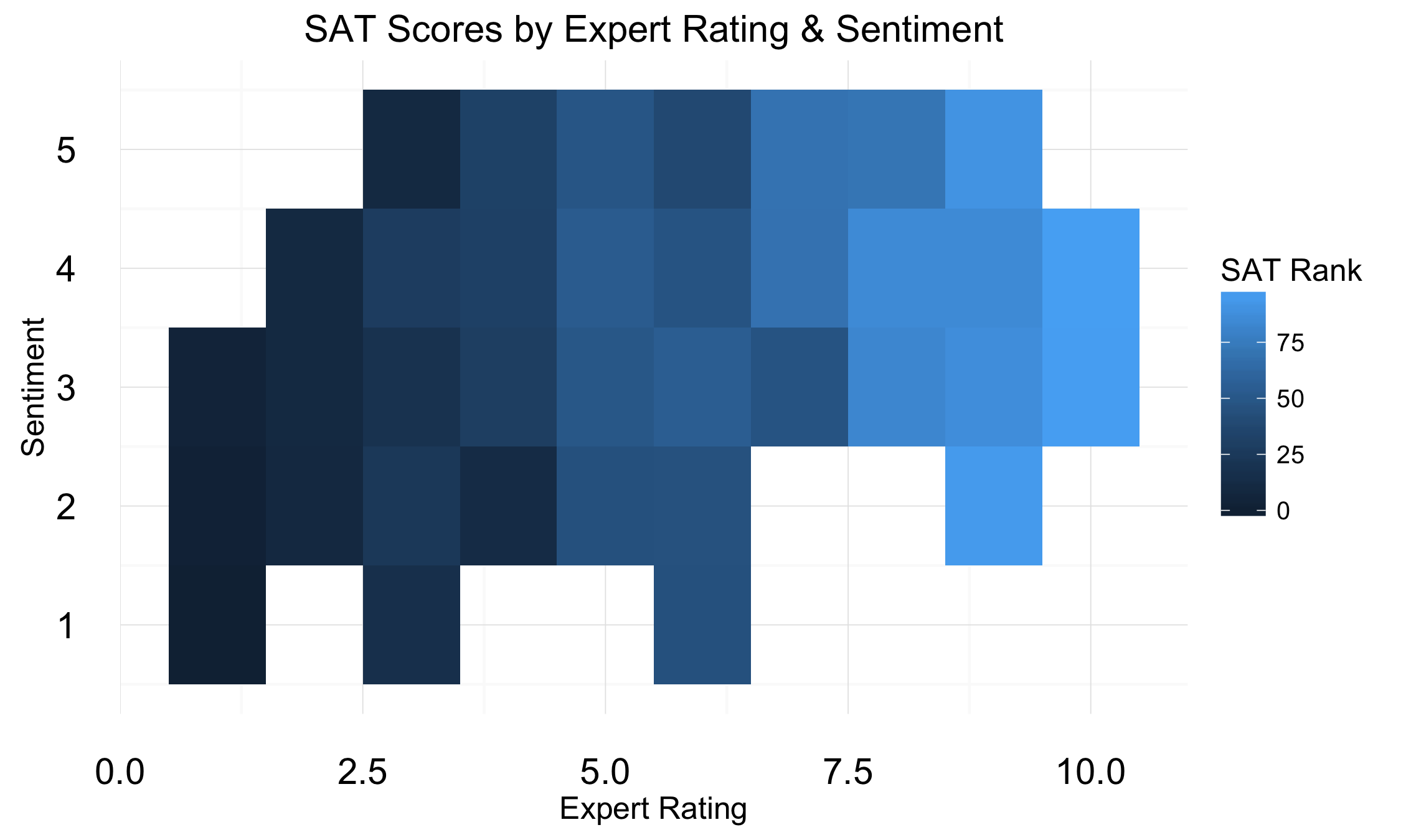
Part 2: Missing but not Random?
While doing EDA, I found that the User Rating field suffered from two kinds of missingness as displayed in the following examples:
| Stars | Review |
| 4 Stars | The teachers at RHS are engaged and effective. As an Alumni of the program I feel my time at the school prepared me for college. |
| 4 Stars | My son is going into his Junior year at MCST, and I am so very grateful that we found this ideal environment. |
| (none) | I give MHS zero stars. MHS is not a place to learn and grow, but an institution that only cares and caters to the overachieving and overprivileged. |
| (none) | My children (one currently a junior, the other a college freshman) received an excellent education at this school. The breadth of courses is impressive. |
Missing stars (aka, user ratings), were missing for two reasons. First, there were people who thought the act of not selecting a star would imply a rating of "zero". However, this is not how the stars were aggregated on the GreatSchools.org website; missing stars simply dropped out. Second, there were either data issues or people simply forgot to select a star rating. Could these rating be imputed to give a more accurate aggregate numerical rating to the school?
To investigate this, I relied on two natural language processing methodologies. First were the Tidy Text lexicons. These unigram (one word) text databases were recently popularized for categorizing the sentiment of Donald Trump's tweets depending on the phone they were broadcast from. I used the Bing and NRC lexicons from Tidy Text. Bing is a binary positive/negative sentiment lexicon developed by Bing Liu, and NRC is a Word-Emotion Association Lexicon -- a crowd-sourced list of English words and their associations with eight basic emotions and two sentiments.
Earlier I demonstrated that the user rating was not related to the traditional metrics of a school. However, are the user ratings related to the emotional content of the corresponding user review? To check this, I relied on the NRC lexicon. Below are a set of emotions and sentiments grouped by increasing user rating. You can see that the more highly rated schools are associated with higher user ratings.
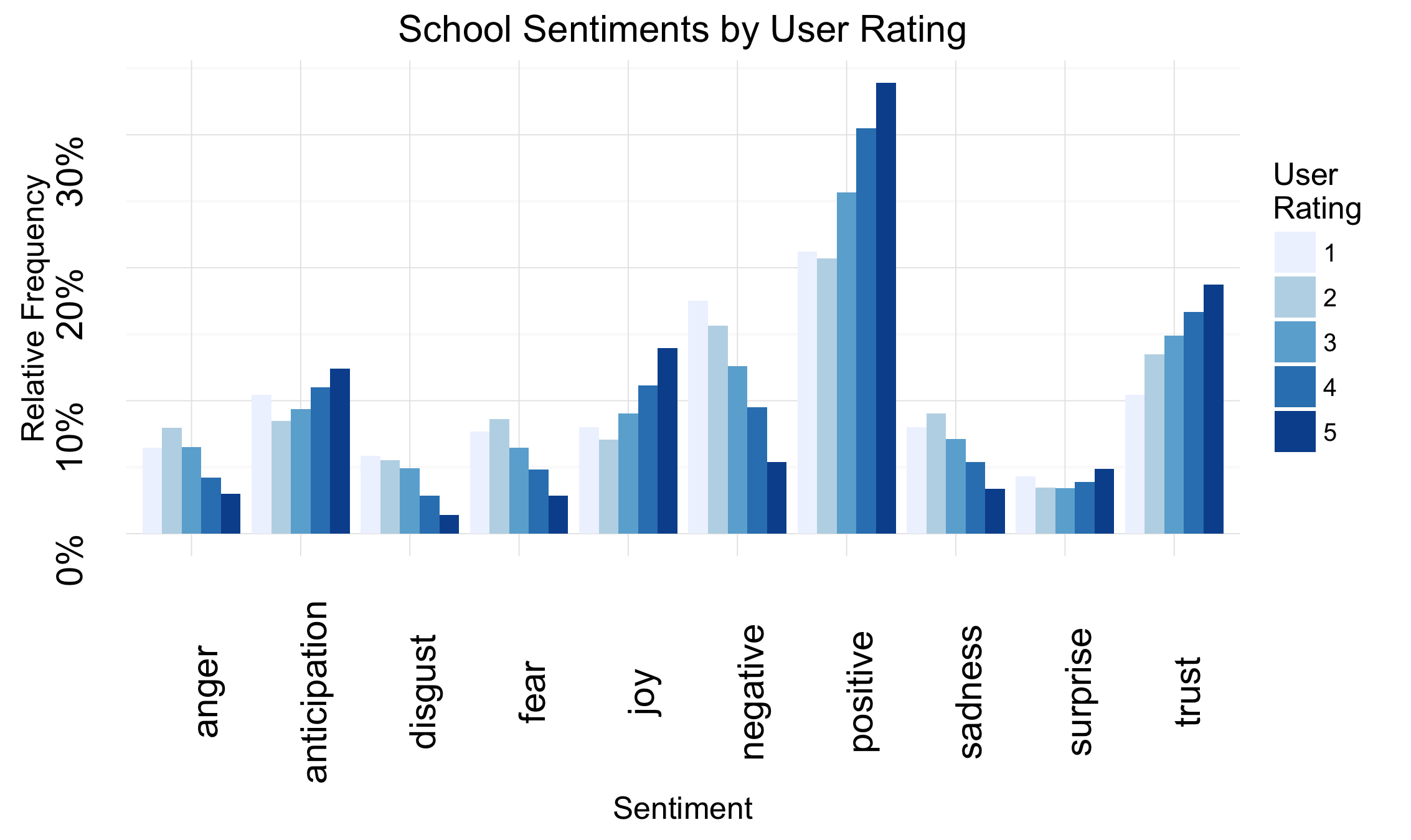
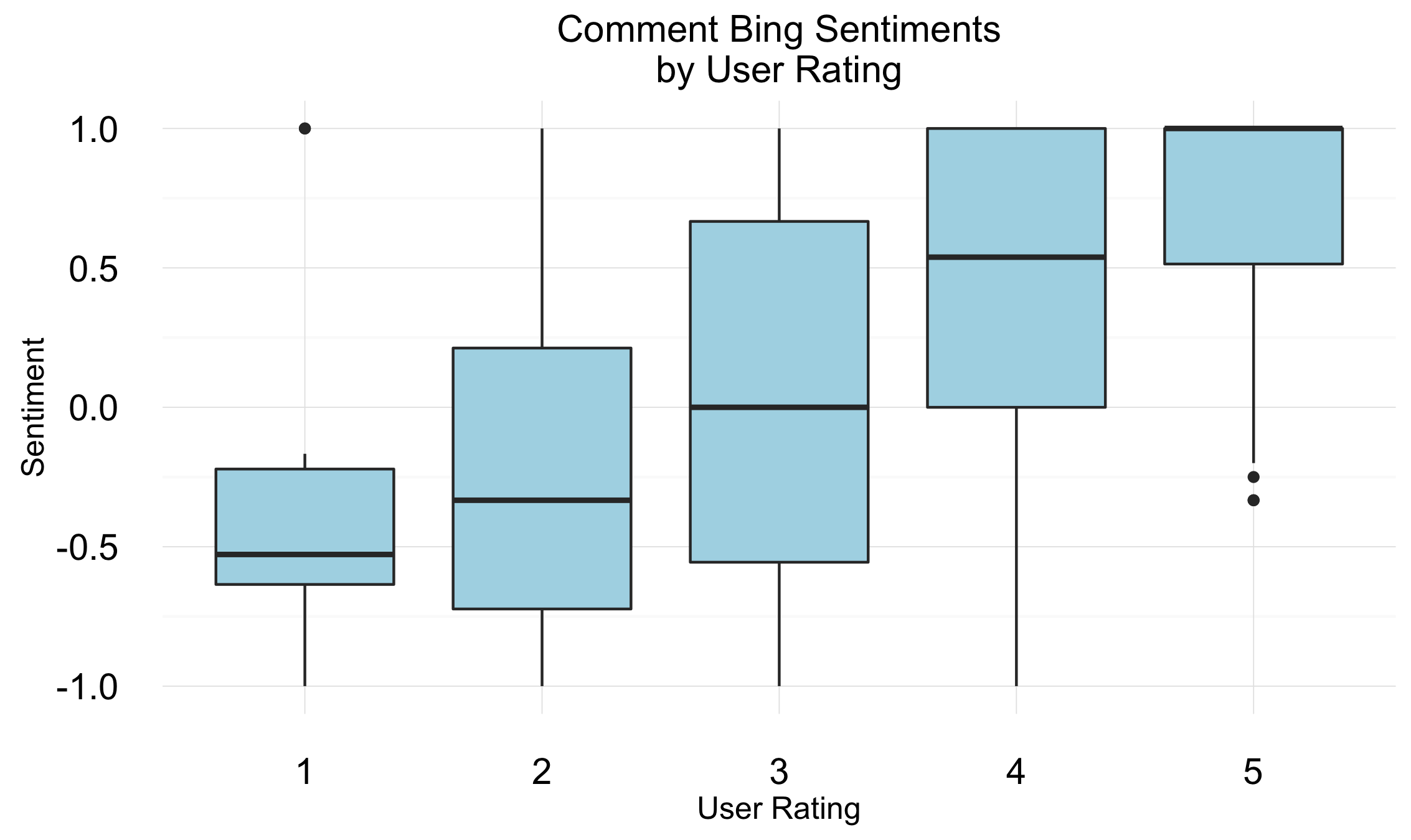
Next, I took the Bing ratings for each word in a given comment and averaged them (normalized over -1 to +1). You can see in the boxplot that the total sentiment increases with user rating. The means of each segment are statistically different and the variance is the same (except for the highest one). This implies that the Bing rating may be a good starting point for imputing user ratings.
Finally, I ran a Naive Bayes algorithm to categorize comments into positive or negative. To do this, I broke out the ratings of 1-2 and 4-5 and labeled them "negative" and "positive", respectively. I would have tried to make more granular ratings, but thought that I needed more than a few thousand comments to train the Bayes algorithm with that level of detail. I then trained the Python Text Blob Bayes algorithm on this data using 2-fold cross-validation (that's all I had time for). And the results? 80% accuracy, with strength in both sensitivity and specificity. Not bad for a first try! Overall, I think between Bayes and Bing, it's possible to come up with a reasonable imputation of the star rating to solve our missingness issue. Other classifier methods would most likely do even better.
| Correct | Incorrect | Total | |
|---|---|---|---|
| Positive | 504 | 124 | 626 |
| Negative | 102 | 27 | 129 |
| Total | 606 | 151 | 755 |
Conclusion
In this project I examined user ratings of public high schools and built a methodology by which to impute missing features of observations. I have two future goals for this project. First, I would like to assess the suitability of other NLP approaches for user ratings imputation. Second, I would like to further investigate schools with high user ratings but low SAT scores. For example, there are schools with the lowest SAT scores in my sample yet with very high user ratings. It would be interesting to assess the corresponding user reviews for classification into a set of themes. For example, it may be the case that some schools may be highly regarded for sports or the fine arts, and this information is not captured in the traditional state metrics. Given the narrowness of the topic of the review, it might be possible to build an algorithm to classify ratings across multiple dimensions. This would provide valuable information to parents choosing a town when relocating.
Topics from this blog: Machine Learning Web Scraping Student Works python scrapy