Objective
For my capstone project, I worked with a group of other students that were sponsored by an organization that works with law enforcement and local communities to reduce intimate partner violence (IPV) in cities across the country. The CDC defines IPV as physical, sexual, or psychological harm by a current or former partner or spouse. I chose to work on this project for two reasons. One is that there is a human element to the data that makes it unique from the other datasets that I have worked with before. The second is that it allows me to use my skills to help an organization that does incredible things. One problem that my sponsor has encountered is that there is not a central repository that collects all of the instances of IPV. A couple of people in my group were working on classifying crime articles as IPV or non-IPV related, and I wanted to see if it would be possible to take the IPV related articles and use natural language processing (NLP) to make classifications using the text from each article.
Initial Dataset
One source of information about IPV that I found was Everytown for Gun Safety, and while researching that group I encountered a study in the form of a census on domestic violence that involved gun homicides in Arizona from 2009 to 2013. The PDF for that study has an appendix with 100 IPV instances, and each instance contains a summary of the occurrence as well as classifications of the instance like whether it involved a shooter suicide or a shooter with a history of domestic violence. I wanted to use these classifications as the responses for the models that I would build using NLP.

Using this PDF, I wrote a parser to grab the contents of the appendix. The parser was a challenge because of the way the text was formatted in three columns that did not always align. But I was able to work around that, and extract a dataset with 100 instances of IPV. Each instance had an associated city, date, text summary, and additional classifiers.
Gathering Articles About Each Incident
From each of these incidents, I used name entity extraction on the text summary to get the full names of everyone involved. For named entity extraction I used both the NLTK and Spacy modules since I found that while individually they missed some of the names, combining the results from the two modules gave a more complete list. With a list of names for each incident I used Microsoft’s Bing API to search for news articles with the full names as keywords. I gathered the urls from the top ten search results and filtered them to remove certain domains like Facebook, Youtube, and the Yellow Pages that were unlikely to contain news about the incident.
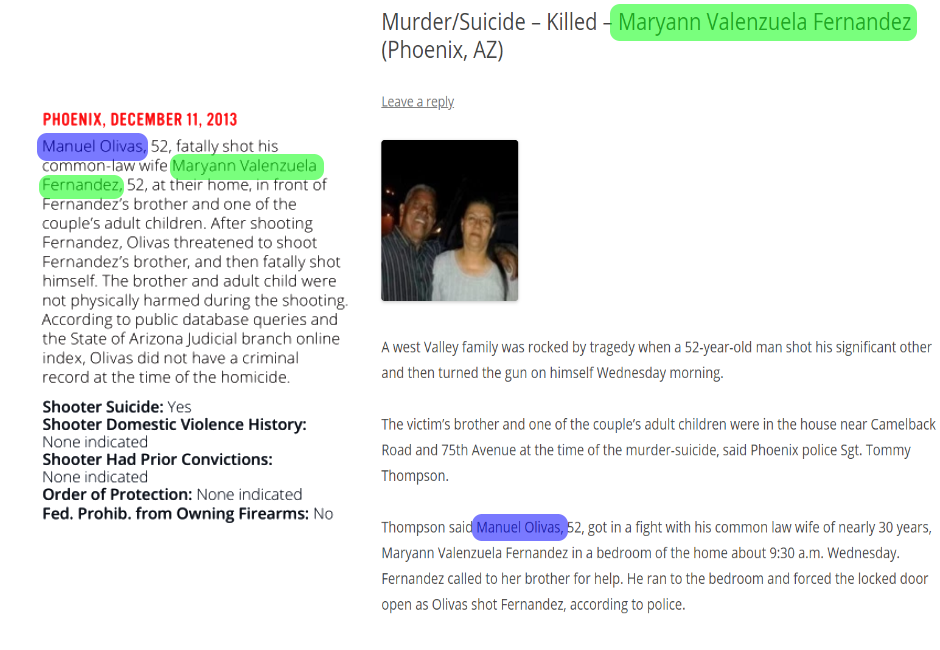
Once I had a set of urls for each incident, I used BeautifulSoup to retrieve the text from each of the urls. With that it was possible to filter the stories to include only the ones were related to the IPV incident. After filtering out the unrelated articles, I had 187 articles about 86 of the incidents that were in the Everytown PDF. I then made the decision to score each article based on the number of times the names from the incident appeared in the article along with typical IPV related words like ”tragedy,” “ gun,” and “shot.” The article with highest number of keywords was selected as the article to do NLP analysis on. In the event of a tie, the longest article would be selected.
Using NLP to Classify Each Incident
With the list of the news articles, I used a term frequency-inverse document frequency (TF-IDF) vectorizer to generate the features for a model that would use a stochastic gradient descent classifier. I employed grid search cross-validation to choose the optimal hyperparameters for each model, and two models were generated with shooter suicide and history of domestic violence as the response for each one. By looking at the value of the coefficients from the models, it’s possible to find the words that are most likely to influence the prediction for each response. The shooter suicide model highlights the words “second degree murder,” “manslaughter,” “charged,” and “ran.” This shows that the model picks up on the fact that if an article mentions someone being charged with crime for the incident then the shooter was captured alive, and the accuracy for this model was about 88%. The domestic violence model highlights the words “order protection,” “judge,” “obtained,” and “convicted.” This shows that the model was influenced by mention of a restraining order being obtained or that the murderer was previously convicted of another crime. The accuracy for this model was 72%.
Future Development
The accuracy rates for the models could definitely be improved with a larger dataset since typical NLP based classifiers use much larger collections of text for training, and mine had less than 100 articles. Other than a larger dataset, future development could also include using different models, such as Multinomial Naive Bayes, or a training set could based on a combination of IPV and non-IPV related articles. Overall these models were just a prototype to show the sponsoring organization what type of classifications could be built on the work that others in my group were doing to obtain IPV related news articles. By combining that article filtering with my classifiers. it could be possible to begin the creation of the type of central database of IPV related incidents that they believe is missing from their work.
Topics from this blog: data science Machine Learning python prediction Capstone Student Works nlp