
Background
For this project our dataset was selected for us. Since it was a Kaggle competition our primary goal in mind was simply to obtain as high of a score as possible on the leaderboard. Our secondary goal was both to exercise and to demonstrate our knowledge of machine learning and apply it to our given dataset.
The main takeaway
Although the data has been anonymized and features obscured, through feature selection we have determined that all the features are needed to help improve our score, none can be eliminated. Additionally, an ensemble method of XGBoost and Neural Networks seems to offer the best results for the competition (our best result placed us in the top 7% on the Kaggle Leaderboard).
Our process
EDA:
For the purpose of cutting down our learning curve regarding the dataset we made extensive use of the forums to read on what methods of EDA people had used to gain basic insights into the dataset. We settled on reproducing specific insights.
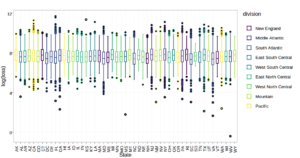 |
Cat116 was shown to be states. Upon comparing the medians of each of the states we drew the conclusion that state from which the claim originated had little effect on the loss column. |
 |
The continuous variables in the dataset do not show a strong correlation with the log(loss)
Note: we took the log of the loss column for the purpose of attempting to find a linear relationship |
Feature Selection
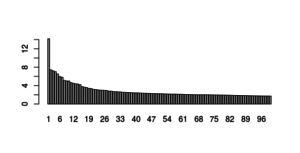 |
We chose to use MCA, a similar technique to PCA but for use with categorical variables. Even with running 100 MCAs none of them showed an Eigenvalue <1 |
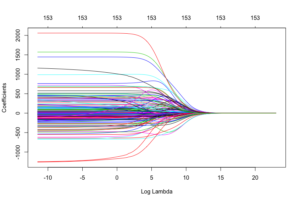 |
From the cross-validation plot, we can find the best lambda value that minimizes the mean absolute error of the ridge regression model. the faster a coefficient shrinks the zero, the less important it is. |
Tools
We made use of AWS Cloud Computing services in our project to overcome the logistical difficulty of lacking enough computing power to run our more complicated models. Our initial trials on our laptops and on our school server crashed every time we attempted to run XGBoost so utilized an AWS based RStudio instance and used our experience from that to run our Neural Net on an Ubuntu instance. For both of these models we ran our script on a subset from the data and ensured it worked before doing the actual run on the On-Demand Instance on AWS.
Further work
Through a combination of utilizing prior knowledge from other Kaggler's EDA and their experience seeing which models worked best we were able to settle on an ensemble of XGBoost and Neural Nets. However, further tuning of parameters in each of these models and in combination with each other is necessary to better our score. There is a methodical approach toward tackling Data Science problems and we hope to use our knowledge gained from trying various models and difficulties in workflow to help us work more effectively and efficiently in future projects.
Topics from this blog: data science Machine Learning Kaggle Student Works XGBoost Neural networks