
Written by Chen Trilnik and Jack Yip. To view the original source code, visit our Github repo here.
I. Introduction
Business Objective
In the last decade, the European Union (EU) economy has been negatively impacted by a series of events, most notably the global financial crisis (2008), the European debt crisis (2009), and the Brexit vote for the UK to leave the European Union (2016). In this era of political instability, investors and companies alike are curious to know whether this is a time of financial opportunity or risk. This analysis aims to assess the economic state of the EU into 2020 using a data science approach.
Gross Domestic Product (GDP) Growth as a Proxy for Assessing Economic State
To answer our business question, we determined that forecasting GDP growth is an appropriate proxy for predicting the overall economic state of the EU. To simplify our analysis, we selected EU countries that, 1) are leaders by total GDP and 2) demonstrate unstable GDP growth in the last decade. We believe this subset of countries is pivotal to the short-term future overall economic state of the EU.
What is GDP?
The gross domestic product (GDP) is one of the primary indicators used to gauge the health of a country's economy. It represents the total dollar value of all goods and services produced over a specific time period.
GDP is often expressed as a comparison to the previous quarter or year. Accordingly, a year-to-year GDP growth of 3% can be read as the economy having grown 3% during the one-year period.
Forecasting GDP can provide valuable information to different groups. For example,
- Stock investors may choose to invest more aggressively in a country where they expect GDP growth to be optimistic
- Foreign manufacturing companies may consider to open a new factory in Europe given a stable GDP growth
About the European Union (EU) and the Eurozone
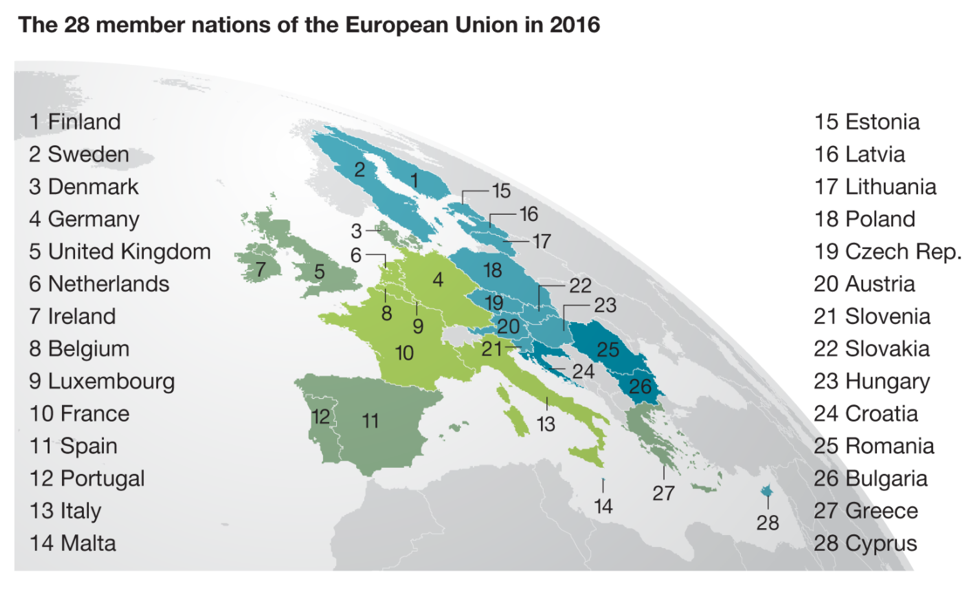
The European Union (EU) is an economic and political partnership among 28 European countries. It was founded after World War II to foster economic co-operation, with the idea that countries which trade together are more likely to avoid going to war with each other. The Eurozone, on the other hand, spans across 19 of EU member countries that use a common currency called the Euro.
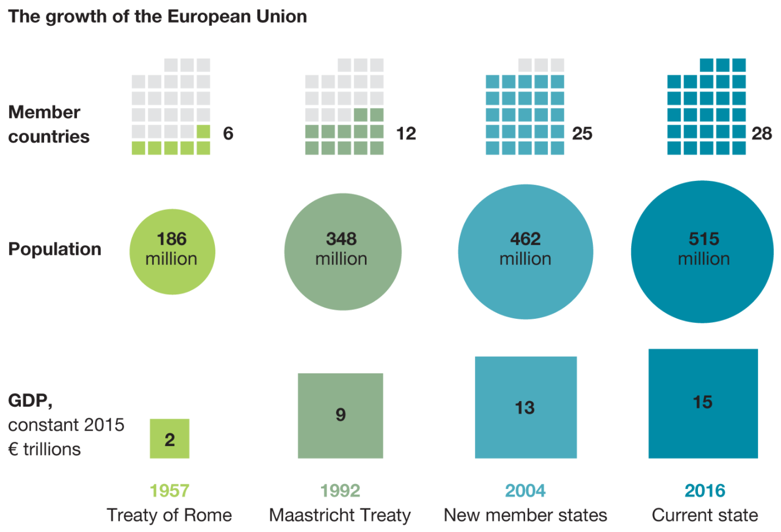
The EU in a Snapshot
Since its establishment, the EU grew from 6 to 28 members, added 300M to its population, and grew GDP by more than seven-folds. (Source)
II. Exploring EU Macroeconomic Data
AMECO Macroeconomic Data
AMECO is the annual macro-economic database of the European Commission. The database contains data for EU-28, the euro area, EU Member States, candidate countries and other OECD countries. In total, AMECO provides annual data points for over 460 macro indicators across 18 categories.

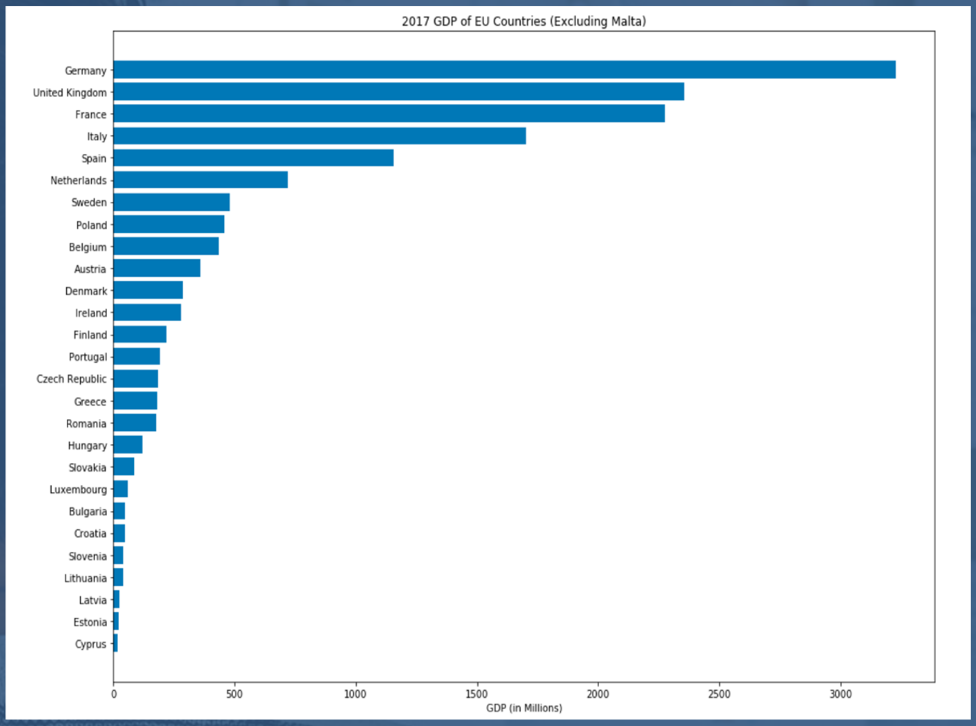
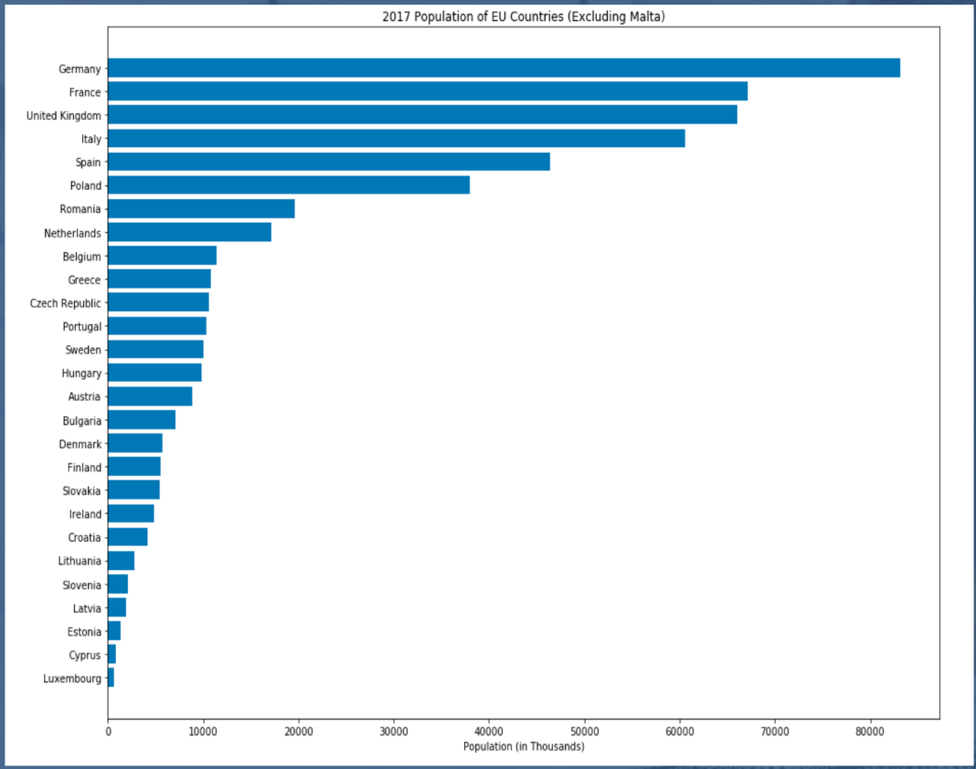
Total GDP & Population Per Country
Germany, France, United Kingdom, Italy, and Spain lead the EU with both the largest GDP and population in 2017.
GDP Per Capita
GDP per capita, a proxy for measuring average individual wealth in a country, varies greatly among the EU members.
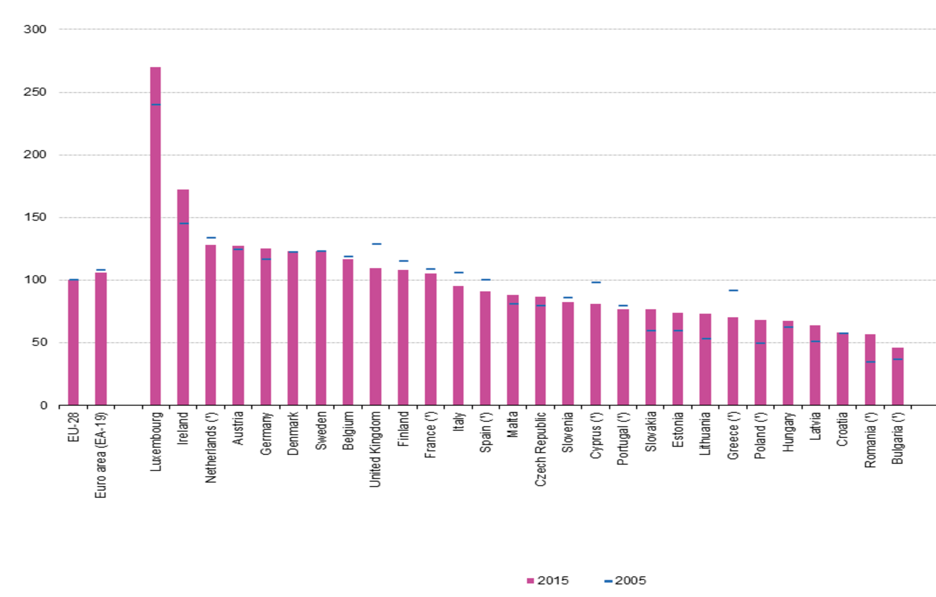
Unemployment Rates in EU Countries
Unemployment rates in the EU are at record highs in the past decade, including Italy and Spain, who contribute a large portion of total GDP in the EU.
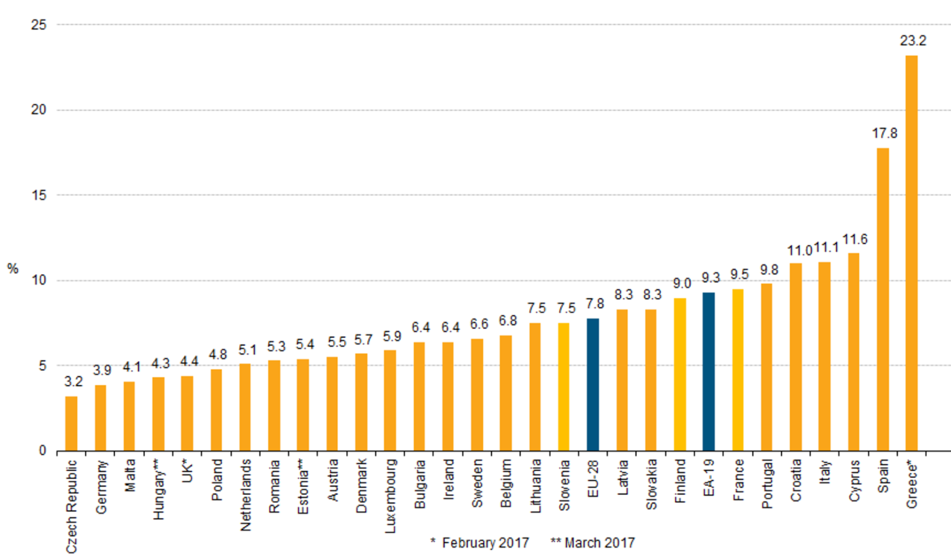
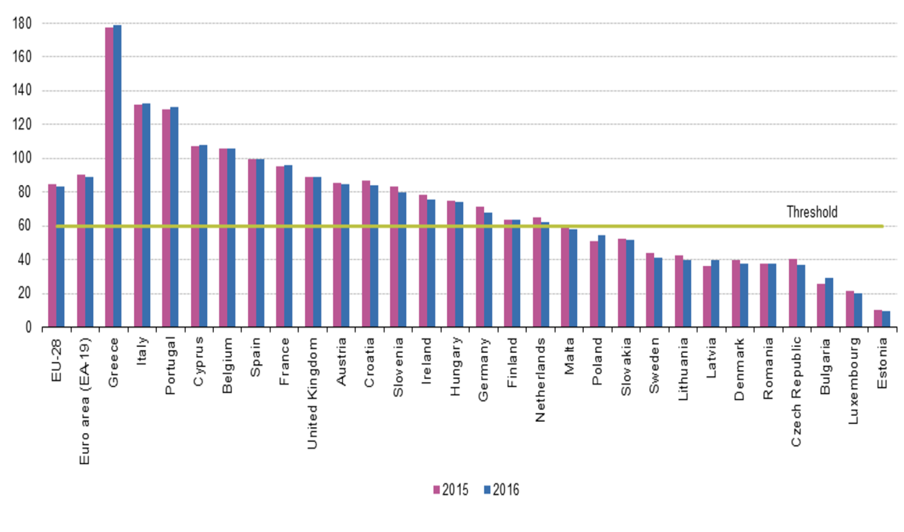
Government Debt As Percentage of GDP
More than half of the EU members exceeded a debt-to-GDP ratio of 60%, which is alarming for developed countries.
III. High-Level Project Workflow
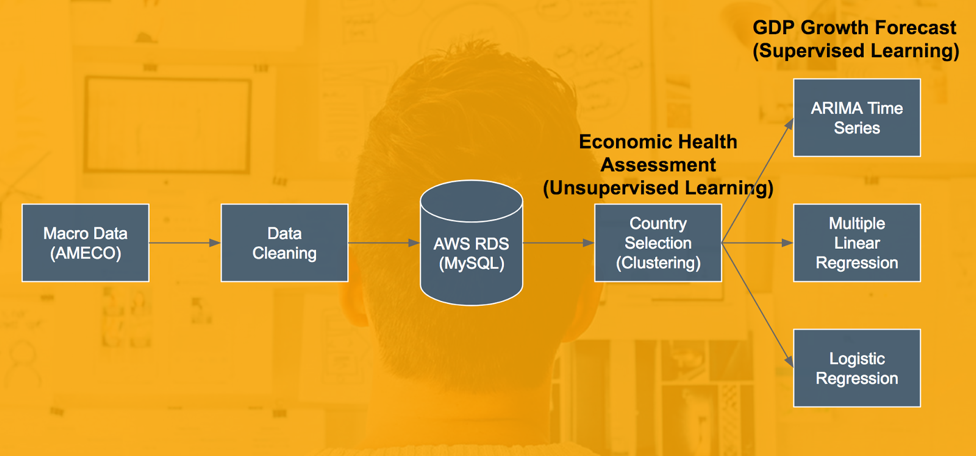
Data Cleaning
The data was restructured to a tidy format where:
- Each variable measured is in one column
- Each different observation of that variable is in a different row
- Additionally, non-EU countries were removed from the analysis.
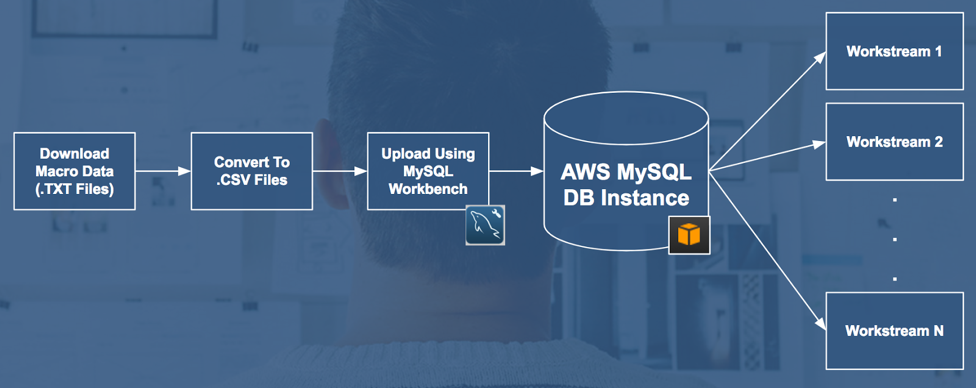
Amazon Web Services (AWS)
Storing our data in a MySQL database through Amazon Web Services Relational Database Services (AWS RDS) facilitates more effective collaboration and allows for reproducible research.
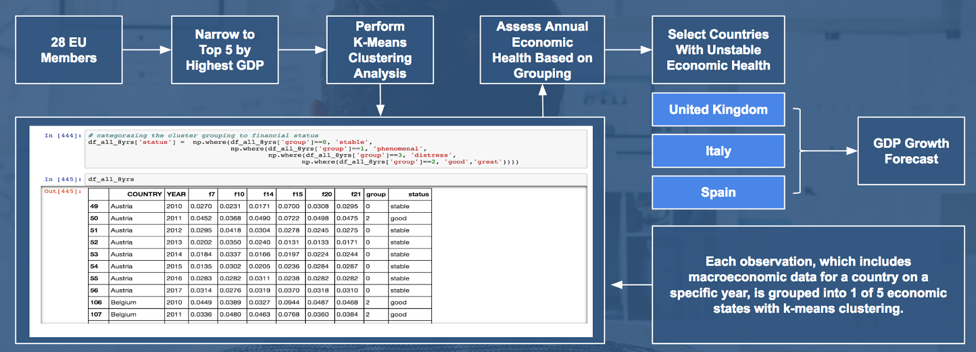
Country Selection Using K-Means Clustering
As mentioned previously, this analysis focuses on EU countries that, 1) are leaders by total GDP and 2) demonstrate unstable GDP growth in the last decade. While the former can easily be determined, k-means clustering was used to assess the latter.
Along with using GDP growth as an input, we determined the five most important macroeconomic features to predicting it (process discussed in the Feature Selection section). Using these six features, k-means clustering was used to group each observation into one of five categories. We interpreted each of these five groups as different economic states a country has shown for a particular year, ranging from very bad to very good.
Of the top 5 EU countries by GDP in 2017, three countries (UK, Italy, and Spain) demonstrated unstable economic states over the past decade (i.e. fluctuations in economic states and/or high number of years with poor economic state.) These countries are selected for further GDP forecast analysis.
IV. Forecasting GDP Growth - ARIMA Time Series
About ARIMA Time Series
The main application of an Autoregressive Integrated Moving Average (ARIMA) model is in the area of short term forecasting, requiring at least 40 historical data points. It works best when the data exhibits a stable or consistent pattern over time with minimum number of outliers.
In our analysis, we have at least 50 historical data points for each of the macroeconomic indicators, which makes ARIMA time series forecasting appropriate to use.
Feature Engineering - Transform to Growth Rates
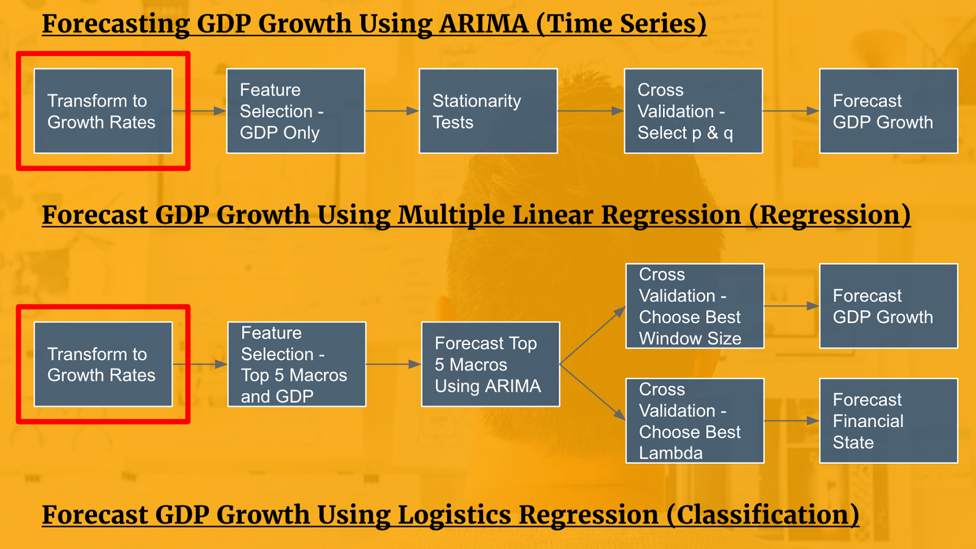
Prior to forecasting GDP growth, we transformed all 460+ features to growth rates. This process acts as a form of standardization to make comparison possible between countries. Additionally, standardization is necessary to mitigate unwanted bias when conducting feature importance such as Lasso shrinkage and predictions using linear regressions.
The example below shows the transformation of the population feature to growth rates.

Feature Selection - ARIMA Time Series
To forecast GDP growth using an ARIMA model, the only feature required is the GDP growth itself.
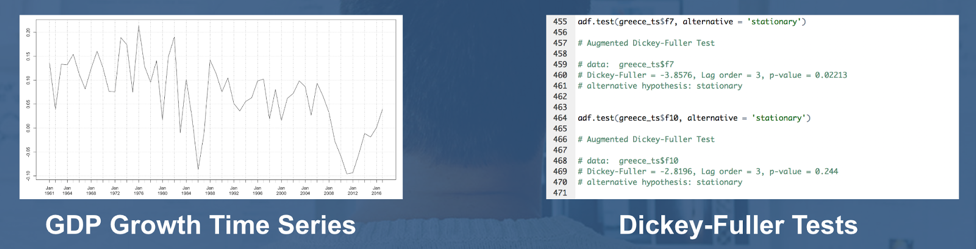
Checking For Stationarity
“A stationary time series is one whose statistical properties such as mean, variance, autocorrelation, etc. are all constant over time. Most statistical forecasting methods are based on the assumption that the time series can be rendered approximately stationary.”
Prior to forecasting, both Dickey-Fuller and KPSS tests were performed to validate the stationarity of the GDP growth rates for each of the three selected countries.
Cross Validation - Select Best p & q for ARIMA Model
An ARIMA model is comprised of three components: Auto-Regressive (AR), Integration/Differencing (I), and Moving Average (MA). These components correspond to the parameters p, d, and q, respectively, when configuring an ARIMA model.
Provided that our GDP growth rates are stationary (d = 0), cross validation can be performed across a range of p and q values to identify an ARMA model minimizing the Schwartz Bayesian Information Criterion (BIC) metric. Essentially, the model with the lowest BIC is more efficient in predictions as it favors models with high accuracy but penalizes models that are complex.
Choosing the best model with the lowest BIC, we forecasted the GDP growth rates for each of the three countries into 2020. The forecasts can be found toward the end of the blogpost.
V. Forecasting GDP Growth - Multiple Linear Regression & Logistic Regression
Limitations with Small Sample Size
When choosing appropriate machine learning models, we took into consideration of the limitations of using a small sample size. As we are limited to less than 60 observations for each feature across each country, it was important to use simpler models to avoid the issue of overfitting.
We determined that using multiple linear regression and logistics regression models were most appropriate for our circumstance. Because these models do not handle complexity very well, we perform feature selection in the next section to limit the number of predictors used to forecast GDP growth.
Feature Selection Using Lasso Regularization & Chi-Square
Of over 460 macroeconomic indicators, the 5 most important predictors of GDP growth were chosen to conduct the forecasts of GDP growth.
Lasso regularization works by weeding out less important features by shrinking their coefficients to zeros using the L1 penalty.
The visualization below demonstrates the shrinkage of the feature coefficients by varying the penalty factor λ.
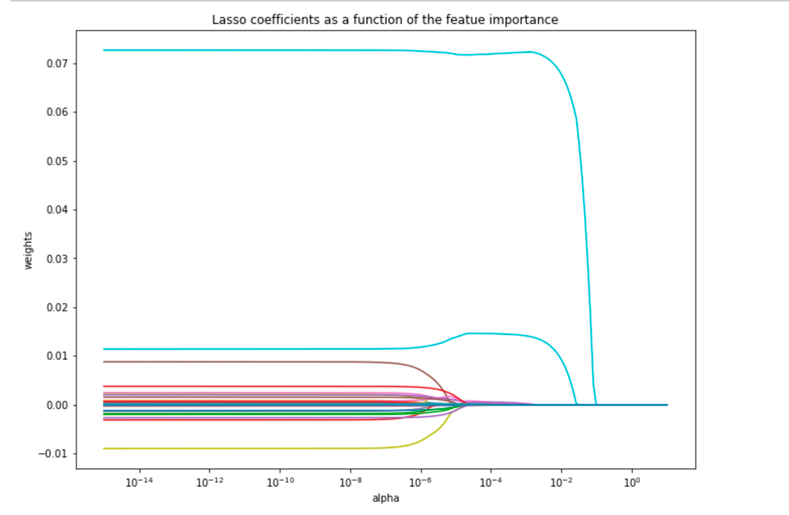
The chi-square test measures dependence between stochastic variables, so using this function weeds out the features that are the most likely to be independent of class and therefore irrelevant for predictions.
The screenshot below on the right side shows the feature importance as determined by the chi-square test.
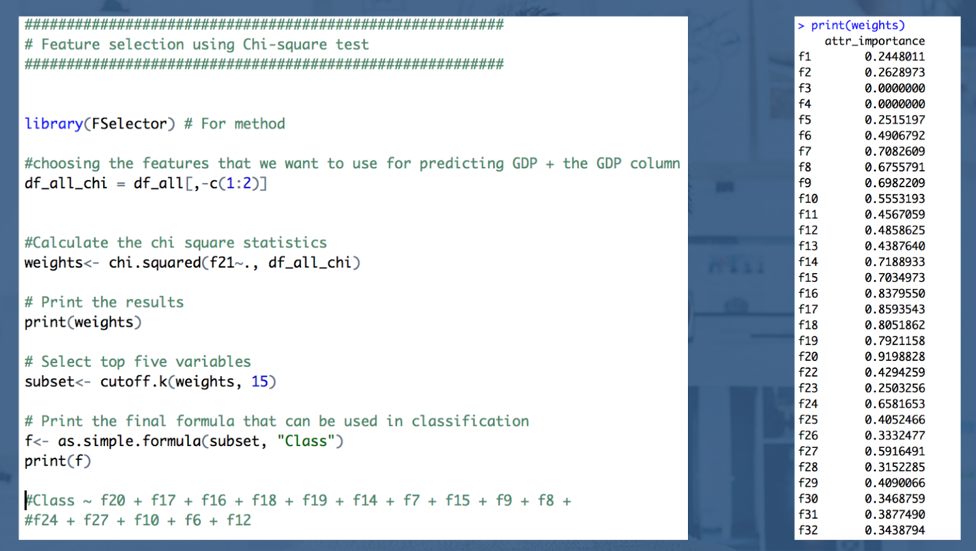
Using lasso regularization and chi-square test for feature importance, we selected the following five features for predicting GDP growth.
Top 5 Features for Predicting GDP Growth
- Private final consumption expenditure at current prices
- Consumption of fixed capital at current prices: total economy
- Domestic demand excluding stocks at current prices
- Final demand at current prices
- Domestic income at current prices
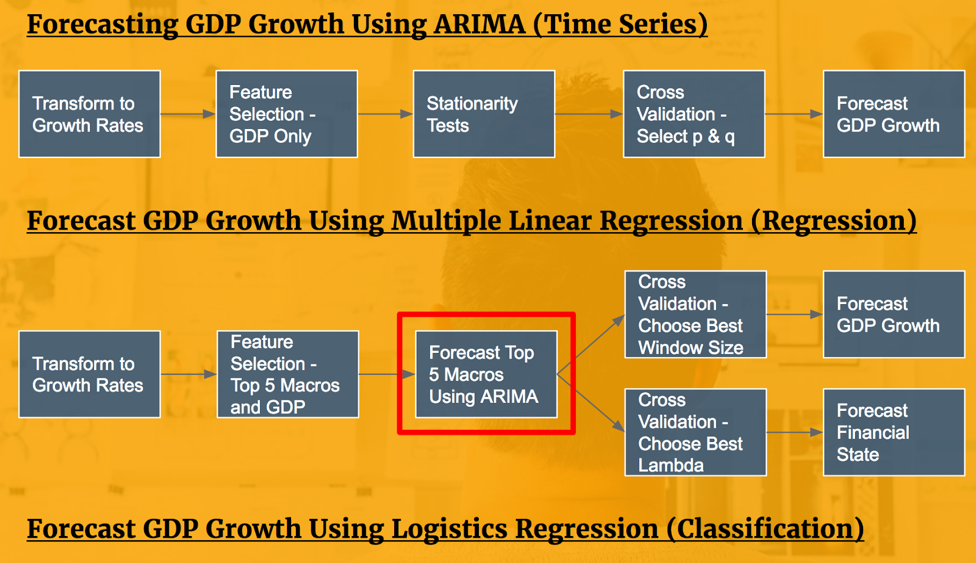
Auto.ARIMA for Forecasting Top 5 Features
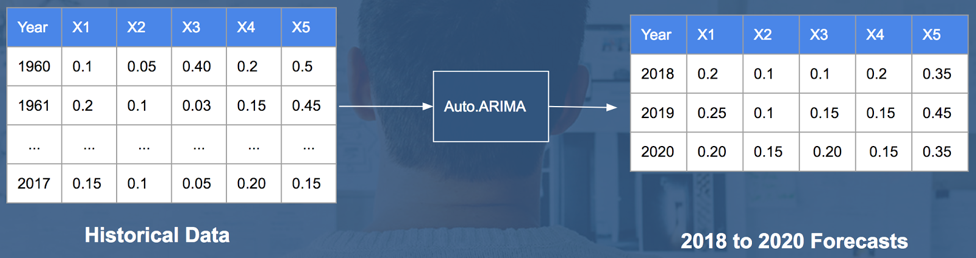
Previously, GDP growth was forecasted using itself as a predictor (i.e. ARIMA time series forecasting). In this section, GDP growth is forecasted using the top five predictors identified during the feature selection process. In order to forecast GDP growth using these predictors, we used the ‘auto.arima’ function from the R ‘forecast’ library to forecast each of these five features into 2020. These forecasted values will help us forecast GDP growth values using a multiple linear regression and logistics regression.
The illustration below shows the process of forecasting each of the five selected features for predicting GDP growth.
Multiple Linear Regression
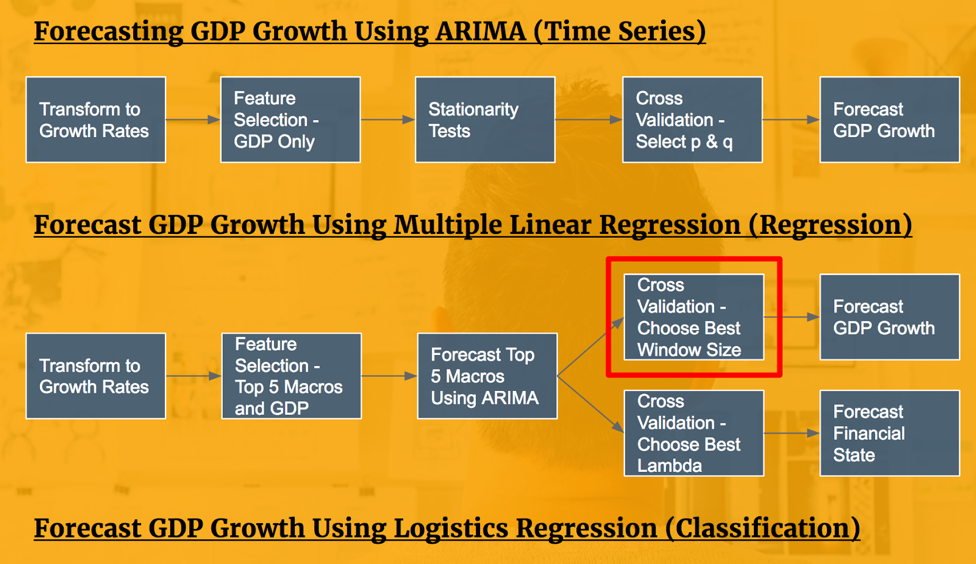
Cross Validation - Select Best Training Window Size
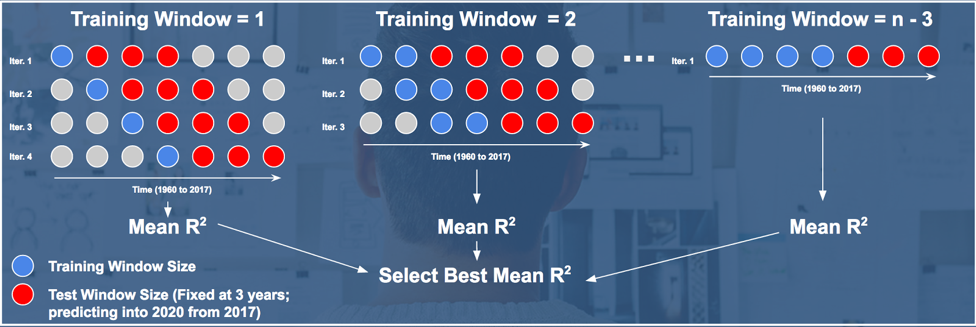
To choose the best multiple linear regression model for forecasting GDP growth, we conducted a cross validation across different training window sizes. Since the features and target variable at hand are time series, using a traditional k-fold cross validation will not consider the time series trend. Instead, we implemented a moving window cross validation.
Fixing the test window size at 3 years, we conducted a cross validation with different training window sizes, from length to 1 to n-3, where n represents the number of observations for each feature. For each training window size, we iterated through the observations using a forward-looking strategy. This avoids predicting past data points using future information. In the end, the mean R2 is evaluated across the iterations.
Forecast With Best Training Window Size
To forecast GDP growth into 2020, we chose the model with the training window size that provides the best mean R2. The forecasts are discussed toward the end of the blogpost.

Logistic Regression
Categorizing GDP Growth
To forecast GDP growth using a logistic regression, we needed to transform GDP growth rates to categories. We did not need to transform the predictors, as only the target variable needs to be in categorical form.
In classifying the GDP growth rates, the median GDP growth of the past 12 years for each country was used as the benchmark. Each year was categorized into either “below median” or “above median.”
The illustration below shows how the GDP growth rates are transformed to categories assuming a median of 0.12.

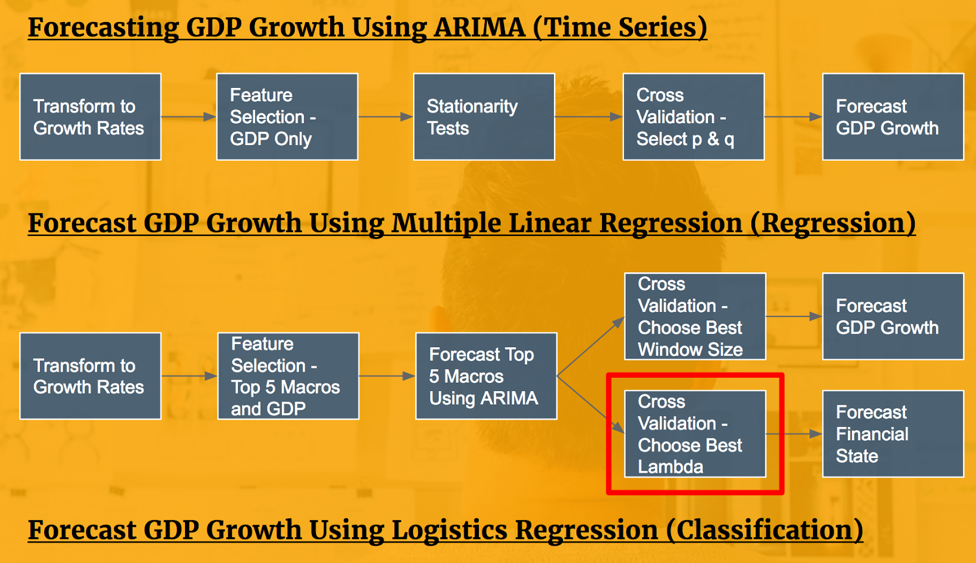
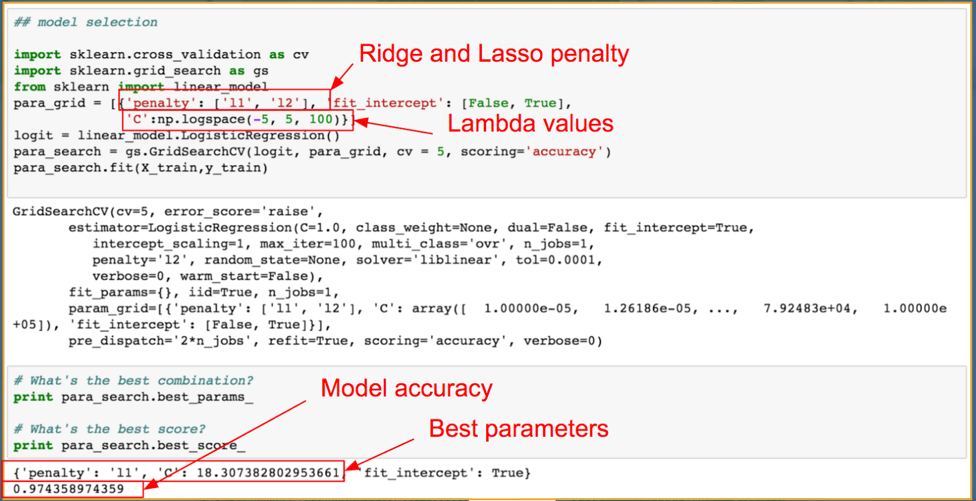
Cross Validation - Grid Search
A grid search cross validation using l1 (lasso) and l2 (ridge) penalty is used across a range of λ values to identify the model with the best accuracy. This model is then used to forecast the GDP growth categories.
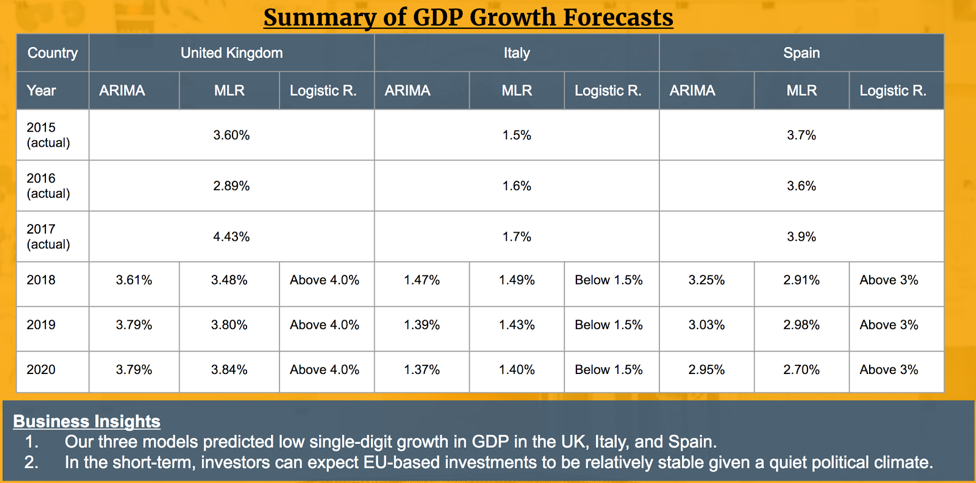
Summary of GDP Growth Forecasts
The table below outlines the forecasts using each of the models discussed for the United Kingdom, Italy, and Spain. The first three rows (2015 to 2017) are actual GDP growths based on historical data from AMECO. The following three rows (2018 to 2020) are forecasts provided by each of the three models (i.e. ARIMA, Multiple Linear Regression, and Logistic Regression).
In summary, our three models predicted positive GDP growths in the next three years for the United Kingdom, Italy, and Spain. Assuming a stable political climate in the near future, foreign investors and companies can expect economic conditions to grow in low single-digit rates.
Topics from this blog: R clustering NYC regression linear regression python prediction Capstone Student Works lasso regression AWS