

Event-Driven Stock-Prediction
Contributed by:
Scott Edenbaum, and Xu Gao
We conducted research into machine learning techniques for financial modeling. We found the following deep learning techniques in are widely used in finance: Shallow Factor Models, Default Probabilities, and Event Studies. As a result, we decided to follow the nontraditional route of analyzing news content to predict the price movement of a stock. in regards to news content, one preliminary finding is that many news titles do not contain impactful information about a company, rather it is used attract readers to increase page-views and ad revenue.
Our project is based on "Deep Learning for Event-Driven Stock Prediction" from Xiao Ding, Yue Zhang, Ting Liu, Junwen Duan. In their research, they use a neural tensor network to transform word embeddings of news headlines into event embeddings, and a convolutional neural network to predict the price trend for one day, week, or month.
Finding consistent news data was surprisingly difficult since we were looking to gather, mostly due to our need for ~5-10 years of historical data to train our model. In addition, there were many anti-scraping techniques in place to trick web scraping programs, such as CAPTCHA requests, and inconsistent XPath structure.
For the news data, we were able to successfully scrape news flow from ~2008 from SeekingAlpha by using a combination of Selenium to 'scroll down' and load new web content, and BeautifulSoup to grab the content from the webpage. In order to avoid generating "split-adjusted" pricing data, and keeping track of ticker changes, we gathered our pricing data from a Bloomberg terminal. For the sake of simplicity, we chose to make the naive assumption that a stock's open price is equal to the previous day's close price, so we only needed to keep track of the close price for our model.
The Java tool, ReVerb was an essential ingredient to our model's recipe. ReVerb identifies binary word relationships and replaces them with a single form. For example the words, "is," "was," and "be," are all transformed into "be" with ReVerb, allowing for a much more robust and less fragmented analysis of the news content.
The output from ReVerb includes a probability, such as 0.8225 in the above example. This probability represents the relevance of the news content to the given stock, not the impact the news will have on the stock.
We used a variety of models for transforming our text into an input for the neural network. Although Doc2Vec performed rather well, there is no clear 'winner' across the board for all the stocks in our analysis.
Our basic model consists of a neural network with 2 hidden layers with a binary output layer. After tuning the parameters, we found the best performance was with two hidden layers, 300 and 50 nodes respectively, both with hyperbolic tangent activation functions.
Usually for event-driven research, only a portion of the news events have an impact on a given stock's return, so we use that stocks market data as a basic dataset. By adding new factors we analyze from news content, we can get a new dataset and build a prediction model.
- Dataset 1: Market Data
- Stock: 5-day lag time series, S&P 500, NASDAQ Composite, and NYSE Volume
- Dataset 2: Dataset 1 + Sentiment Polarity (ie: positive, neutral, negative)
- Sentiment polarity is generated with the TextBlob package in Python
- Dataset 3: Dataset 1 + Word Embeddings (ReVerb)
- For news with multiple sub-headlines, we chose the sentence with the highest confidence level
- Subject, Object, and Verb "tuple" form word embeddings
- For news with multiple sub-headlines, we chose the sentence with the highest confidence level
- Dataset 4: Dataset 1 + Word Embeddings (all news content)
- Entire news content is converted to single vector using Doc2Vec in Gensim package
- all information is preserved unlike Dataset 3
- Entire news content is converted to single vector using Doc2Vec in Gensim package
Our results were fairly consistent across the 4 models (note Doc2Vec ALL includes news content from all stocks), and not too surprising, the inclusion of 'excessive' and unrelated information negatively impacts model performance.
Results:
- Aggressive Strategy:
- Predict up -> long 1 unit
- Predict down -> short 1 unit
- Protective Strategy:
- Predict up -> long 1 unit
- Predict down -> close position (sell long)
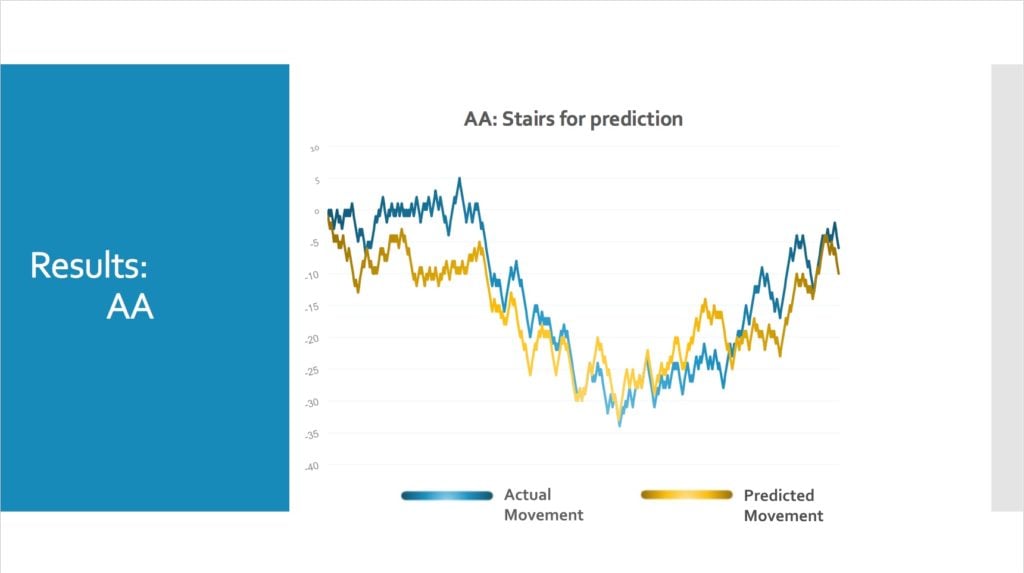
Our prediction matched very closely with the actual stair movement for AA.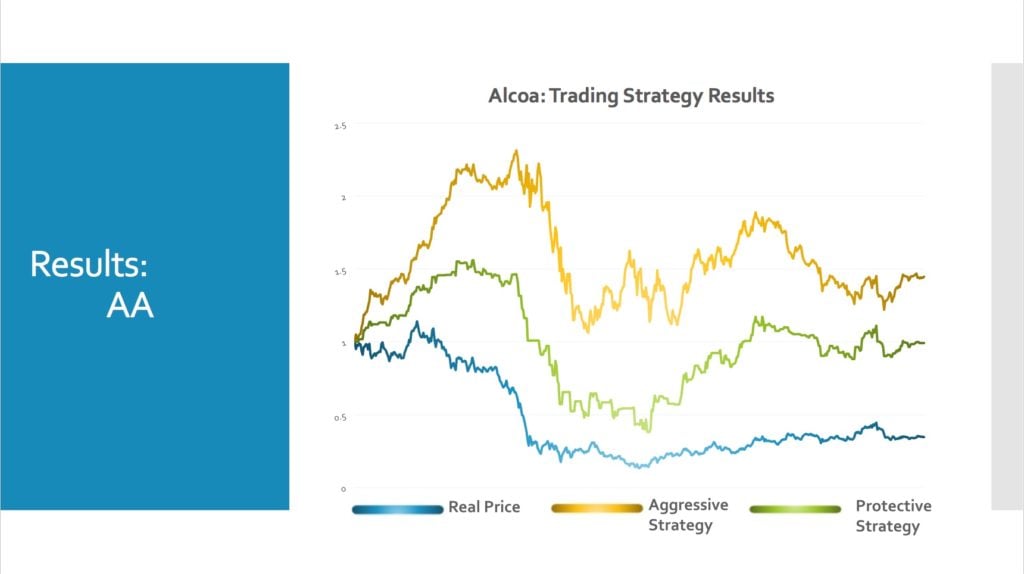
{kind=link}
Our model prediction for AAPL was weaker than some of the other stocks, perhaps that is due to the much higher frequency of news content that is generated for AAPL.
{kind=link}
{kind=link}
The main conclusions from our project are that even with a far from ideal news source, there is an enormous amount of content available that can assist in accurately modeling stock price movement without any fundamental or technical analysis. I believe that with a professional news source (such as Reuters or Bloomberg) coupled with use of corporate actions calendars (dividends, splits, earnings releases, etc) would lead to significant improvements on our current model.
Complete PDF Presentation Slides: EDSP-presentation
Topics from this blog: R NYC neural network python prediction Web Scraping Capstone Student Works Selenium nlp