Best Values for Grocery Shopping.
Price analysis at Keyfood, CTown and freshdirect Supermarkets using Python.
A few Results:
- Keyfood and C-Town "on sale" prices are approximately the same in the Harlem neighborhood.
- freshdirect is 138% more expensive than C-Town on a basket of 18 common grocery items.
- freshdirect is 146% more expensive than Keyfood on a basket of 10 common grocery items.
Please note that only the same items on sale from Keyfood and C-Town were compared with the fresh direct regular prices.
(Please see further analysis at the end of this post)
--------------------------------------------------------------------------------------------------------------------------------------
Author and Project:
- Author: XAVIER CAPDEPON
- Xavier was a student of the Data Science Bootcamp#2 (B002) - Data Science, Data Mining and Machine Learning - from June 1st to August 24th 2015. Teachers: Andrew, Bryan, Jason, Vivian.
- The post is based on his "Web scraping" (Python) project final submission.
--------------------------------------------------------------------------------------------------------------------------------------
A. Project Context and Analysis:
1. Context:
A few years ago, I moved further North in Manhattan and ended up living in the heart of Harlem on 145th street. Unlike Upper West Side where I was living with roommates a few years earlier, it quickly appeared to me that all the grocery supermarkets were attracting customers based on hypothetical large discounts that they would advertise with large letters on their front windows or with paper weekly circulars that are distributed inside and outside the stores.
After learning the weekly pattern of the discounts in different stores during the first few months, I had memorized a list of prices - that could vary over time - for my most regular grocery items and tried to optimize my spending by shopping for the lowest price items in up to 5 closest supermarkets in my neighborhood. The process sounded quite rewarding to me in terms of spending but quite energy consuming, time consuming and sometimes frustrating.
For the first Python project, I realized that I could compare more quantitatively the prices in different grocery store using the web scraping tool to download all the available data. This first project gave me several technical and theoretical problems to solve that I will explain in this blog post.
2. Preliminary observations:
During this grocery shopping experiment, I observed some curious coincidences:
1. The first one was a curious coordination in terms of items on sale between the different supermaket brands and some similarities in term of prices and period of sales.
2. The second coincidence that I noticed two years ago is the fact that some heavily discounted such as the Tropicana Orange Juice in the standard size (59oz) and all the organic milk brands were never on sale at the same time.
3. Preliminary research and preparation:
Prior to coding, I made some research and I realized that most of the large brands such as Fairway Market would not advertise their prices online at all, or, like Associated Supermarket, the weekly circular discount offerings will be published using a basic scanned picture making the web scraping impossible.
Among the possible choices for the supermarket brands, I selected two brands which are independent and competing in North Manhattan, Keyfood and C-Town, and that are known to attract client with weekly discounts:
- C-Town is "a chain of independently owned and operated supermarkets operating in the northeastern United States" (source Wikipedia) which most of the stores are located in New York, NJ, PA, CT and MA.
- Keyfood is a "cooperative of independently owned supermarkets" (source Wikipedia) which most of the stores are located in the tri-state area.
- freshdirect is an online grocery store which are mainly operating in New York area.
The Fresh Direct scraping wasn't part of the original plan. Surprised by the data scraped on the Keyfood and C-Town website and despite the time left before delivering the project, I decided to scrap Fresh Direct in order to get more data to compare to even if their business plan is slightly different: Fresh Direct hasn't any store and doesn't attract customers by using weekly discount.
The expected data to be captured for this analysis was all available information about grocery items:
- full item name
- full item description
- item price
- item weight/volume
- diverse: picture, price by weight/volume
B. Coding and Strategy:
1. Scraping strategy:
At first, I scraped the Keyfood website, then worked on the C-Town website and finished on the Fresh Direct Website.
All 3 websites had some similarities in term of structures with the existence of a secondary website uncovered during the web scraping coding.
 Key Food:
Key Food:
The solution retained was scraping the index page URL and modifying it about 90 times to download all the grocery items. To extract the data, Regular Expression and Beautiful Soup were used with respectively 20%-80% .
C-Town:
Using the secondary Index URL modified 4 times, an embedded Java script code that contained all the targeted text containing all the grocery items was downloaded using Beautiful Soup. Given the nature of the text, I had to extract all the data Regular Expression only. The website regexr.com
freshdirect
With the experience acquired by scraping Keyfood and C-Town websites, the fresh direct website was slightly easier than the previous two websites. The preliminary strategy to download the data was again through the index page and amend the index category 400 times into the URL.
2. Code:
Initialization:
## initiate packages needed for web scraping
import pandas as pd
import numpy as np
from bs4 import BeautifulSoup, Tag
import requests
import re
# define fonction to extract raw text from website using Beautiful Soup
def extract_text(urlv, headersv):
# Request by url and headers
demande = requests.get(urlv,
headers=headers).text
# Request status code
statut_demande = demande.status_code
if statut_demande/100 in [4,5]:
return 'error on requests with error: ', statut_demande
return BeautifulSoup(demande)
Phase 1: Download the text from the Home page
# Home page URL of the Fresh Direct website
url = 'https://www.freshdirect.com/index.jsp'
# headers used to launch the "requests" fonction from the requests package
headers = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'en-US,en;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
# cookie
'Cookie':'FDUser=1AIA7NG8IVEIH1SRL09ASVBXEK1CUNBK6PQA77J; cmTPSet=Y; CoreID6=80004000370614348352657&ci=90391309; RMID=0a3704045585d940; CM_DDX=pla14=1434835274869; JSESSIONID=tp0MVGQJVh7YTZHNJvrp1GVzjLj9pT1m31vwJw7ZTz5pcw2n8mp1!-1687515818!839018455; _gat=1; _ga=GA1.2.1044717069.1434835264; 90391309_clogin=v=1&l=1434845216&e=1434847301314; RES_TRACKINGID=345160034252330; RMFS=011Z6Su5U10451; RES_SESSIONID=373535453341901',
'Host':'www.freshdirect.com',
'Referer':'https://www.freshdirect.com/browse.jsp?pageType=browse&id=pate&pageSize=30&all=true&activePage=1&sortBy=Sort_PopularityUp&orderAsc=true&activeTab=product',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.81 Safari/537.36'
}
#Using my own fonction defined earlier, the text of home page is extracted in a var named textextracted
textextracted = extract_text(url,
headers)
print textextracted.prettify
The text downloaded contained all the grocery item categories that will be used later to get the targeted data about the grocery items.
Phase 2: Preparation of the extraction of the grocery item categories
## Selection of text containing pertinent information
content0 = [i.__str__() for i in textextracted.find_all('script')]
#print content0
#1. Extraction of Category String using Regex (using regexr.com as starter)
print type(content0)
#### Extraction of full strings
cat = re.findall('("id":"[A-Za-z_]+","name":"[A-Za-z0-9s&é,-']+","image":"/media/images/navigation/department/[0-9a-zA-Z]+)', content0[20])
#### Delete unuseful part of strings
cat3 = [re.sub('"id":"','',x) for x in cat]
cat4 = [re.sub('","name":"[A-Za-z0-9s&é,-']+","image":"/media/images/navigation/department/[0-9a-zA-Z]+','',x) for x in cat3]
print 'cat4:', cat4
cat5 = list(set(cat4))
print type(cat5), len(cat5)
#2. Extraction of Category Full Name
#### Extraction of full strings
catname = re.findall('("id":"[A-Za-z_]+","name":"[A-Za-z0-9s&é,-']+","image":"/media/images/navigation/department/[0-9a-zA-Z]+)', content0[20])
#### Delete unuseful part of strings
catname4 = [re.sub('"id":"[A-Za-z_]+","name":"[A-Za-z0-9s&é,-']+","image":"/media/images/navigation/department/','',x) for x in catname]
print catname4
catname5= list(set(catname4))
print catname5, len(catname5)
## Simplified list of category index:
cat5 = list(set(cat4))
Note: the above code doesn't catch all the pet food categories.
Phase 3: run tests using the item category "jarsause" that contains all the pasta sauces available at fresh direct.
## 'url2' is a generic URL used as a basis:
## - the page size is modified for 'pageSize=500' and
## - the category index is contained in the string 'id=jarsauce'
url2 = 'https://www.freshdirect.com/browse.jsp?pageType=browse&id=jarsauce&pageSize=500&all=true&activePage=1&sortBy=Sort_PopularityUp&orderAsc=true&activeTab=product'
headers2 = {
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':'gzip, deflate, sdch',
'Accept-Language':'en-US,en;q=0.8',
'Cache-Control':'max-age=0',
'Connection':'keep-alive',
'Cookie':'FDUser=1AIA7NG8IVEIH1SRL09ASVBXEK1CUNBK6PQA77J; cmTPSet=Y; CoreID6=80004000370614348352657&ci=90391309; RMID=0a3704045585d940; CM_DDX=pla14=1434835274869; JSESSIONID=qyjWVGYQBJPQ2cL1SkSn4TcmLQTX78zlJHvGJP9pJdQSjnJyQ5qh!1352730708!-1129265067; RMFS=011Z6UNu; _ga=GA1.2.1044717069.1434835264; 90391309_clogin=v=1&l=1434851351&e=1434853650199; RES_TRACKINGID=345160034252330',
'Host':'www.freshdirect.com',
'Referer':'https://www.freshdirect.com/browse.jsp?pageType=browse&id=pate&pageSize=30&all=true&activePage=1&sortBy=Sort_PopularityUp&orderAsc=true&activeTab=product',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.81 Safari/537.36'
}
textextracted2 = extract_text_keyfood(url2,
headers2)
#print textkeyfood2.prettify
Note: the standard pageSize=30 string in the URL is modified pageSize=500 to get all the information available at once.
Phase 4: tests and preliminary loops to extract the grocery items data
#### tests of data extraction
content00 = textkeyfood2.find('div', class_="browse-sections transactional")
#print 'len c00:', len(content00), content00
content001 = content00.find_all('li')
print 'len c001:', len(content001), #content001
#print content00[0], 'n', content00[1], 'n', content00[2]
content01 = [x.find('a', class_="portrait-item-header-name").get_text() for x in content001]
#content02 = 0 #content001.find_all('div', class_="configDescr")
#content03 = 0 #content001.find_all('div', class_="portrait-item-price")
#### actual loop
listitemFullName = []
listitemPrice = []
listitemDescription = []
i=0
for x in content001:
Fullname = x.find('a', class_="portrait-item-header-name")
Price = x.find('div', class_="portrait-item-price")
Descr = x.find('div', class_="configDescr")
if Fullname==None:
listitemFullName.append('NA')
else:
listitemFullName.append(Fullname.get_text())
if Price==None:
listitemPrice.append('NA')
else:
listitemPrice.append(Price.get_text())
if Descr==None:
listitemDescription.append('NA')
else:
listitemDescription.append(Descr.get_text())
print 'name', len(listitemName)
print 'name', len(listitemFullName)
print 'price', len(listitemPrice)
print 'descr', len(listitemDescription)
print 'name', listitemName
print 'fullname', listitemFullName
print 'price', listitemPrice
print 'desc', listitemDescription
Note 1: the code extract a list of redundant item categorical strings that is reduced to 347 item categorical strings that will be used to modify the generic URL (https://www.freshdirect.com/browse.jsp?pageType=browse&id=jarsauce&pageSize=500&all=true&activePage=1 &sortBy=Sort_PopularityUp&orderAsc=true&activeTab=product') by replacing the "jarsauce" string
Note 2: not all the pages have the same architectural structure under the "class_="browse-sections transactional"". In order to show and understand the details of the architecture, I used the following code which confirmed that a few pages had a different structure:
## Since the findAll function doesn't provide the expected data,
## an analysis of the architecture of the targeted class "browse-sections transactional" is needed
## Bryan code to draw the tree architecture: var: maxdepth horizontal, maxbreadth vertical and attrs,keys / items()
content00 = textextracted2.find('div', class_="browse-sections transactional")
def take(n, iterator):
'''Take the first n items from a generator'''
return [x for _, x in zip(range(n), iterator)] #hacky?
def treeWalker(bsobj, level = 0, maxdepth = 5, maxbreadth = 20, indent = ' '):
'''Pretty printer with limits on depth of printing'''
if level >= maxdepth:
print indent * level, 'reached max depth'
return
if hasattr(bsobj, 'children'):
children = take(maxbreadth, bsobj.children)
for item in children:
if isinstance(item, Tag):
print indent * level, item.name,
if len(item.attrs) > 0:
print item.attrs.items() ### change keys() or items()
else:
print ''
treeWalker(item, level + 1, maxdepth, maxbreadth)
if len(children) == maxbreadth:
print indent * level, '[', len(bsobj.contents) - maxbreadth, 'tags not printed ]'
treeWalker(content00)
for i in range(0,len(content00)):
if content00.find_all('li', class_="portrait-item-header-name")<>None:
listitemFullName.append(content00.find_all('a', class_="portrait-item-header-name").get_text())
else:
listitemFullName.append('NA')
if content00.find_all('li', class_="configDescr")<>None:
listitemDescription.append(content00.find_all('div', class_="configDescr").get_text())
else:
listitemDescription.append('NA')
if content00.find_all('li', class_="portrait-item-price")<>None:
listitemPrice.append(content00.find_all('div', class_="portrait-item-price").get_text())
else:
listitemPrice.append('NA')
Phase 5: Generate the 354 URL corresponding to all the grocery item categories:
url3 = 'https://www.freshdirect.com/browse.jsp?pageType=browse&id=jarsauce&pageSize=1200&all=true&activePage=1&sortBy=Sort_PopularityUp&orderAsc=true&activeTab=product'
print url3
urllist = []
for i in range(0, len(cat5)):
category = 'id='+ cat5[i] ### defined above on phase 1
#print category
new_url = re.sub('id=jarsauce',category,url3)
urllist.append(new_url)
print urllist
print len(urllist), len(urllist)/10
Phase 6: finalization of the code to scrap the entire inventory of grocery items:
%%time
####### Complete download for Fresh Direct based on single address amended 400+ times ##############
listitemName = []
listitemFullName = []
listitemPrice = []
listitemDescription = []
listitemCategory = []
for l in range(0, len(urllist)):
if l in[10,50,100,200,300,400,500]:
print l
else:
False
textkeyfood2 = extract_text_keyfood(urllist[l], headers2)
content00 = textkeyfood2.find('div', class_="browse-sections transactional")
#print 'len c00:', len(content00), content00
if content00!=None:
content001 = content00.find_all('li')
if content001!=None:
#print 'len c001:', len(content001), #content001
for x in content001:
Fullname = x.find('a', class_="portrait-item-header-name")
Price = x.find('div', class_="portrait-item-price")
Descr = x.find('div', class_="configDescr")
if Fullname==None:
listitemFullName.append('NA')
listitemCategory.append('NA')
else:
listitemFullName.append(Fullname.get_text())
listitemCategory.append(cat5[l])
if Price==None:
listitemPrice.append('NA')
else:
listitemPrice.append(Price.get_text())
if Descr==None:
listitemDescription.append('NA')
else:
listitemDescription.append(Descr.get_text())
else:
False
else:
False
print listitemName
print listitemFullName
print listitemPrice
print listitemDescription
print listitemCategory
Note: the code runs for about 15 min and generates all the grocery items description, prices and additional information
Phase 7: the data is transferred into a data frame and saved on the disk:
## creation of new dataframe of lists of caracteristiques created above
import pandas as pd
import numpy as np
fdirect_data = pd.DataFrame({'name': listitemFullName,
'desc': listitemDescription,
'price': listitemPrice,
'category': listitemCategory })
fdirect_cat_data = pd.DataFrame({'item_name': cat4,
'category': catname4})
#listeCtownCat = pd.DataFrame({'name': listlinksCategories2})
fdirect_data.replace(u'’', u"'")
fdirect_data.to_csv('./fdirect_data3.csv',sep=',',encoding='utf-8')
#listeCtownCat = pd.DataFrame({'name': listlinksCategories2})
fdirect_cat_data.replace(u'’', u"'")
fdirect_cat_data.to_csv('./fdirectcatdata3.csv',sep=',',encoding='utf-8')
3. the output files:
All the output files and the code for the 3 web scraping including the output file for the freshdirect web scraping can be found here.
C. Data Cleaning and Analysis
1. Data Cleaning:
Given the time frame to deliver the project and my background, I, unfortunately, used Excel to clean and match the data (heavy Vlookup combined with Paste value) that makes the cleaning and matching not completely reproducible.
The Cleaning consisted in homogenize the item names ,cleaning the prices in dollars versus the ones in cents.
The preliminary analysis consisted in finding exact matching between the three data set obtained by web scraping.
2. Analysis:
fig. 1 code:
data = pd.DataFrame({'Supermarkets' : ['Ctown','Keyfood','Fresh Direct'],'references' : [308,411,8370]})
plt.rcParams['figure.figsize'] = 12,9
data.plot('Supermarkets','references',color=['y', 'r', 'g'],kind='bar')
plt.title('Numbers of product references n obtained by webscraping n')
plt.text(-.02,500,'308')
plt.text(.98,600,'411')
plt.text(1.98,8600,'8,370')
fig.1: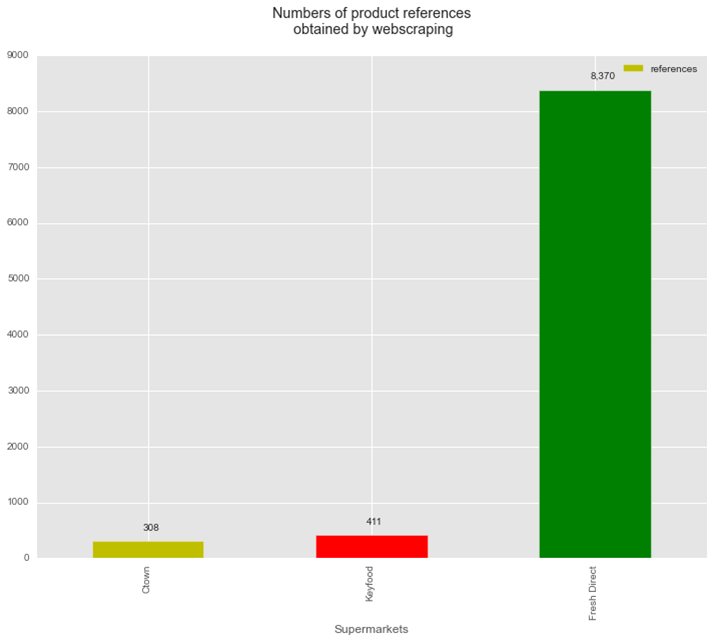 Above (fig. 1): After cleaning and removing all the duplicates, the web scraping of the 3 websites are summarized by the graph above: 308 single items are available on sale at CTown, 411 items on sale at Keyfood and 8370 single items on regular price at Fresh Direct.
Above (fig. 1): After cleaning and removing all the duplicates, the web scraping of the 3 websites are summarized by the graph above: 308 single items are available on sale at CTown, 411 items on sale at Keyfood and 8370 single items on regular price at Fresh Direct.
fig. 2 code:
df = pd.concat([ctown.priceFinalCT,keyfood.PriceKFF,fdirect.priceFDt1], axis=1)
df.columns=[ 'C Town (Weekly Circular)', 'Key Food (Weekly Circular)','Fresh Direct (Online)']
moyenne1 = df.mean()
fdirectcatgroup = fdirect.groupby('categoryFDS')
keyfoodcatgroup = keyfood.groupby('CategoryKF')
ctowncatgroup = ctown.groupby('categoriesCT')
plt.rcParams['figure.figsize'] = 12, 8
plt.subplot(221)
df.boxplot(vert=False)
plt.xlim([-2,25])
plt.xlabel('Price ($)')
plt.title('Grocery Supermarket Prices n (week of June 23 2015)n')
plt.scatter(moyenne1,[1,2,3], marker='+')
plt.subplot(222)
fdirectcatgroup.count().nameFD.plot(kind='bar')
plt.xlabel('')
plt.ylabel('number of items')
plt.title('Fresh Direct Categories')
plt.subplot(223)
ctowncatgroup.count().nameCT.plot(kind='bar')
plt.xlabel('')
plt.ylabel('number of items')
plt.title('C Town Categories')
plt.subplot(224)
keyfoodcatgroup.count().nameKF.plot(kind='bar')
plt.xlabel('')
plt.ylabel('number of items')
plt.title('Key Food Categories')
plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=.5)
left = 0.125 # the left side of the subplots of the figure
right = 0.9 # the right side of the subplots of the figure
bottom = 0.1 # the bottom of the subplots of the figure
top = 0.9 # the top of the subplots of the figure
wspace = 0.2 # the amount of width reserved for blank space between subplots
hspace = 2 # the amount of height reserved for white space between subplots
fig. 2:
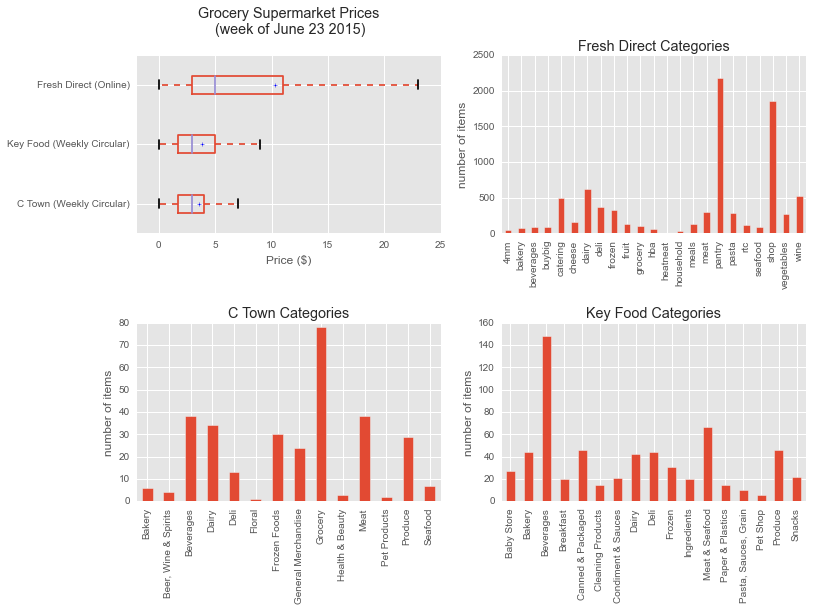
Above (fig. 3): the graph shows that the price range of the items on sale at Keyfood and CTown are similar (about $5) whereas the average of the regular prices at freshdirect are twice higher (about $10). Looking at the fresh direct prices data, we can observe that there are a lot of items from the catering department that push the average price up. Despite my expectations, it is really difficult to do an analysis by grocery categories given the different distribution for each brand.
fig. 4-5-6 code:
#### plt.rcParams['figure.figsize'] = 12,3
plt.subplot(131)
toto2 = kffd.Category.groupby(kffd.Category).count()
toto2.plot( kind='pie')
plt.title('Match Categories n')
plt.subplot(132)
kffd.boxplot()
plt.scatter([1,2],[kffdm1,kffdm2], marker='+')
plt.ylim([0,8])
plt.title('Avg, Median prices by Supermarket n')
ax = plt.subplot(133)
plt.bar([1,2],[kffds1,kffds2],0.4,label=('Key Food','FreshDirect'),align='center')
ax.set_xticks([1,2])
ax.set_xticklabels( ('Key Food','FreshDirect') )
plt.text(.90,kffds1-5,'$32.43', color='w')
plt.text(1.90,kffds2-5,'$47.12', color='w')
plt.tick_params(
axis='x', # changes apply to the x-axis
which='both', # both major and minor ticks are affected
bottom='on', # ticks along the bottom edge are off
top='off', # ticks along the top edge are off
labelbottom='on')
plt.title('Basket Price by Supermarket n')
#help(plt.bar)
#plt.subplots_adjust(left=None, bottom=None, right=None, top=None, wspace=None, hspace=.5)
left = None # the left side of the subplots of the figure
right = None # the right side of the subplots of the figure
bottom = None # the bottom of the subplots of the figure
top = None # the top of the subplots of the figure
wspace = .5 # the amount of width reserved for blank space between subplots
hspace = None # the amount of height reserved for white space between subplots
plt.subplots_adjust(left, bottom, right, top, wspace, hspace)
fig. 4-5-6:
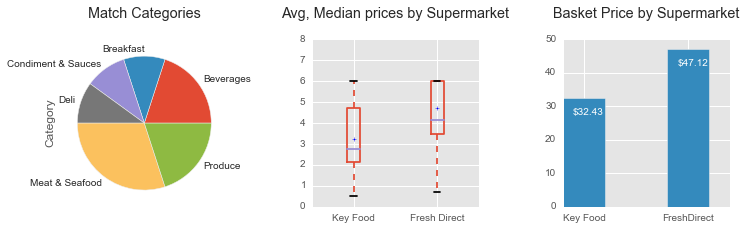
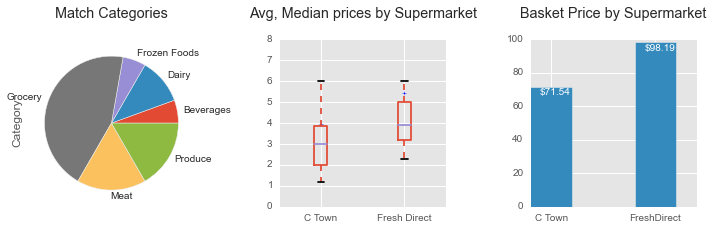
Calculation are based on a basket of 10 identical items identify at both Keyfood and freshdirect
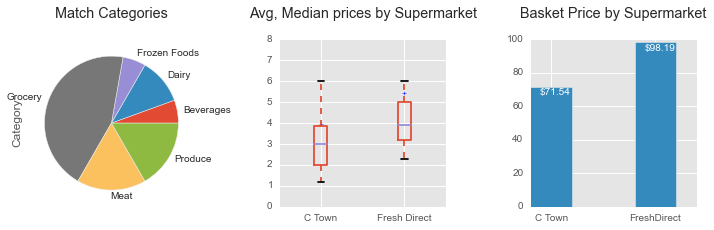
Calculation are based on a basket of 18 identical items identify at both Keyfood and freshdirect
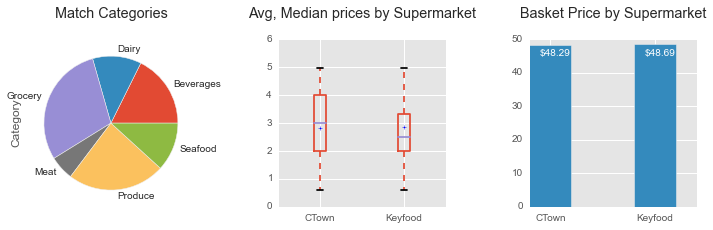
Calculation are based on a basket of 17 identical items identify at both Keyfood and freshdirect
- Keyfood and C-Town "on sale" prices are approximately the same in the Harlem neighborhood, which confirmed my preliminary observation regarding the similarity of prices between the two brands.
- freshdirect is 138% more expensive than C-Town on a basket of 18 common grocery items.
- freshdirect is 146% more expensive than Keyfood on a basket of 10 common grocery items.
Please note that items on sale from Keyfood and C-Town are compared to the same items at the regular price at freshdirect.
D. Conclusions and Observations:
It appears that the prices differences between Keyfood or Ctown are 70% of the regular prices at freshdirect and that a basket of 10 identical items at Keyfood and Ctown is similar in terms of price.
However, it was not possible to compare the full prices of the items available in the Keyfood or Ctown as the two brands would not disclose the data. After a few visits at Keyfood and CTown, it also appeared that the average price of the same item on sale and at the full price may be equivalent to the regular price at freshdirect (example: the price observed on the Tropicana Orange Juice (see presentation)). This would need to be confirmed by more observations.
The data are also showing the two coincidences mentioned in the introduction:
1. There is a curious coordination in terms of items on sale between the different supermaket brands and some similarities in term of prices and period of sales: the period of sales are similar and the data are showing similar prices on similar items.
2. Some heavily discounted such as the Tropicana Orange Juice in the standard size (59oz) and all the organic milk brands are never on sale at the same time: it was the case during the week of the web scraping.
Finally, the data raised the question about the margins on the different products by the different brands, their advertisement practices and their inter-dependence in term of prices.
Possible Improvements and analysis:
It is disappointing to find only 10 to 20 exact matches between the three brands but a better coding algorithm than the excel vlookup may provide more matching.
It may be interesting to study the prices by zip code for the different brands.
the fresh direct website contains all the information about nutrition, so it would be possible to analyse the grocery item prices versus their nutriments.
Topics from this blog: Web Scraping Student Works