
Introduction
We were interested in using customers' information to predict their purchasing behaviors on retail market and insurance industry. As we know the data for customers are confidential so it is hard to obtain such data. For the capstone project, we decided to use Airbnb dataset from kaggle to predict where will a new guest be booking their first travel destination based on the user booking behaviors and demographic information. We performed data cleaning, data process, exploratory data analysis, and machine learning on the project.
Exploratory Data Analysis
Let's look at the gender distribution to see if there is any relationship with the target (destination).
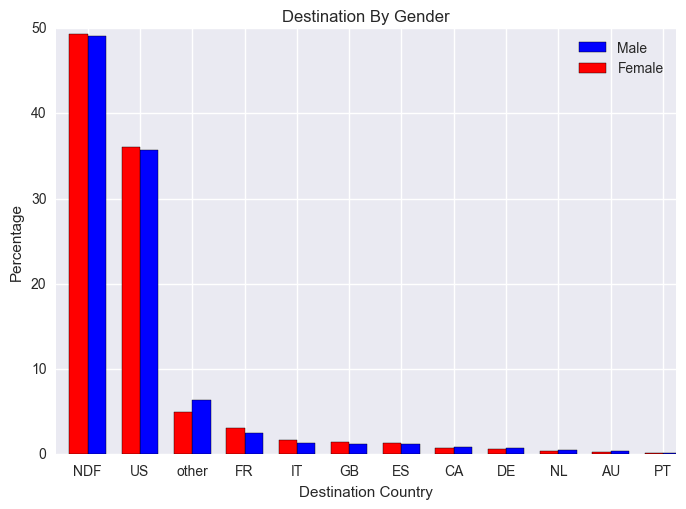
There is no difference between male and female for the booking rate. NDF (No Destination Found) have the highest rate. US has the highest booking rate among all other known countries, from this we conclude people make booking for national trips more than international trips. The plot also showed the dataset is imbalanced clearly.
Next, we look at the age distribution.
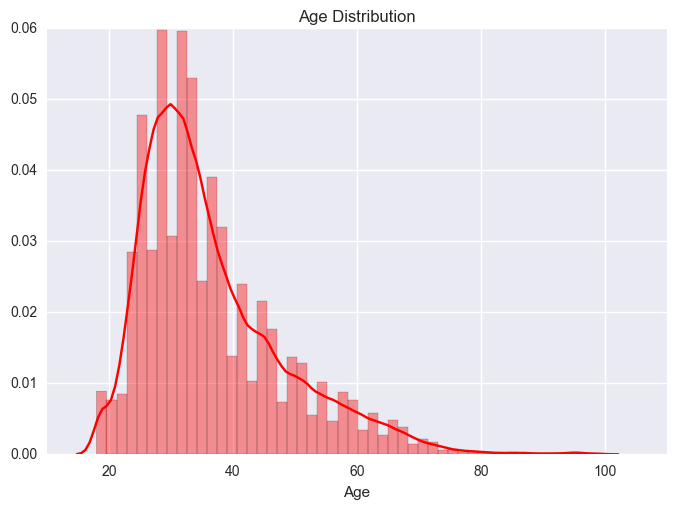
The age is left skew. People made their first booking in the late 20s and early 30s more comparing with other age range.
We also look into their booking behaviors to see if there is any pattern.
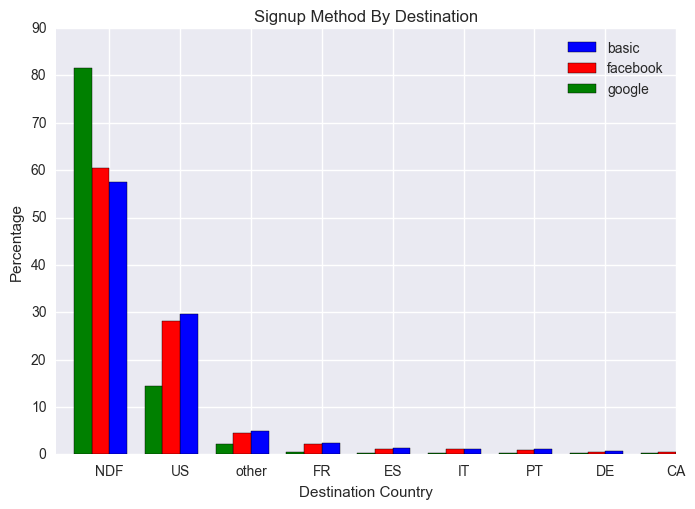
People use website directly to book more than the other two social media platforms. Facebook brings in higher traffic than google overall. Its because of the ads in Facebook which drives a lot of traffic to Airbnb.
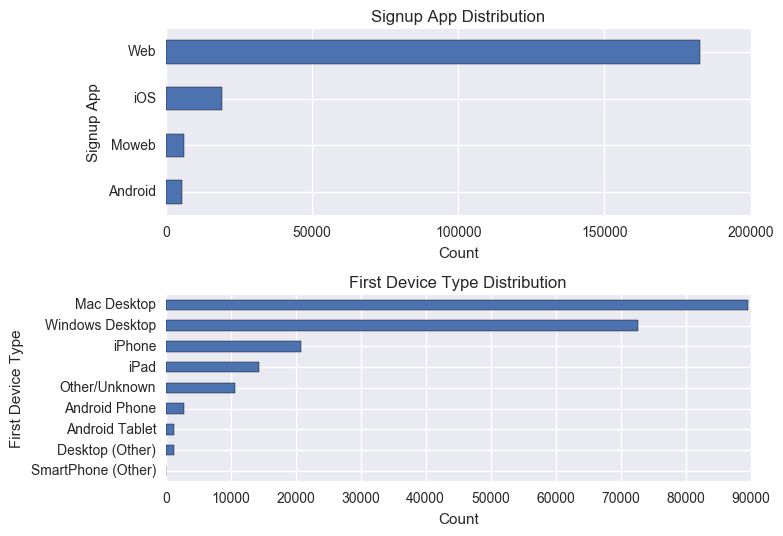
People who use web are more serious in making their booking than those who use other apps. Similarly, those people who use desktop are more likely to book.
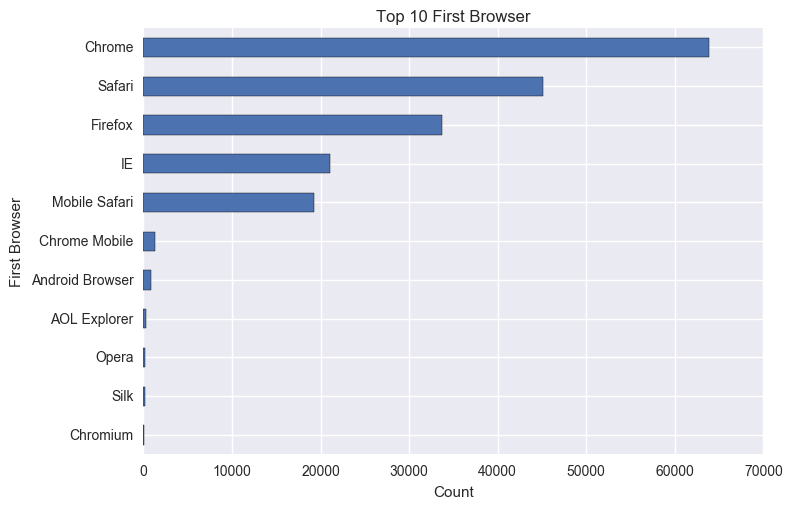
The top 10 first browser plot shows chrome as the number one browser used to book and which is true from our experience. Safari and Firefox are following it.
Let's look at the time frame for the customers on making their first booking:

There were peaks in September for the years of 2010 and 2011. People made their first booking more on August for the years of 2012 and 2013. The booking for 2014 and 2015 are not quite normal. Starting from Jun 2014, bookings were dropped dramatically. In 2015, the bookings decreased at a constant rate. So this might be due to missing data during that period.
Feature Importance
We use extratrees classifier to do the feature importance. Extra-trees differ from classic decision trees in the way they are built. When looking for the best split to separate the samples of a node into two groups, random splits are drawn for each of the max_features randomly selected features and the best split among those is chosen. When max_features is set 1, this amounts to building a totally random decision tree.
The booking time elements play an important role in the prediction. Age is also another important factor for the prediction.
Data Cleaning
Few of the columns in the dates had invalid value. We cleaned out the data to NaN. Age column had some noise so we chose to keep age range from 18-99 and transform the other values to NaN. For the sessions dataset we grouped the dataset by user and aggregated the seconds elapsed by action, action type, action detail and device type. Then the values were transposed to columns and finally merged to the User dataset.
Upsample and Downsample
Since the data was imbalanced we tried to upsample and downsample with SMOT but didn't yield good results so we decided to take the probabilities for each of the class and just use the top 5 class to make our predictions. Some algorithm allowed to input the weight parameter for each of the class as well.
Model Selection
We decided to go with tree based models since logistic regression doesn't work well if you don't have linearly separable boundaries. So we decide to use Random Forest, Ada Boost, Gradient Boosting & XGBoost. For all the model we did cross validation by splitting the train/test as 80/20 split. We did Grid Search to choose the optimized parameter.
With Random Forest we achieved an accuracy of 0.81870
With AdaBoost we achieved an accuracy of 0.8439
With Gradient Boosting we achieved an accuracy of 0.8321
Finally using XGBoost we achieved an accuracy of 0.85359
Conclusion
From all the models we tested tree based models gave us the best accuracy.
Topics from this blog: R NYC Machine Learning Kaggle prediction Capstone Student Works XGBoost airbnb random forest