
Introduction
The crawler is comprised of several different components to make the unstructured data accessible for cleaning. As the data we are looking to scrap here is financial in nature, we take on several webpages to comprise and give the data structure. First, the structure is given with two feats, its endpoints or URLs and the writing of features for further analysis. Both processes we will describe in full to explain with further visualizations.
Unstructured
The first set of data takes on a relative amount of information pertaining to each URL from a home's designated webpage. These URLs are scrapped and written to commas separated valued that can be read in by a separate function. Through Google Chrome's driver the initial arguments were passed through a list. While these strings are not the complete endpoints, we reformat each in the designated list to iterate through the various needed websites.
Considering the site has JavaScript embedded into at least its user interface (UI) then Selenium was the chosen tool after attempting with Beautiful Soup and the less cumbersome tools. The file must run through a shell to test an XPath's endpoint. Other, or sometimes older, programming interface can be seen to work depending on how a website has been built. Regardless, trail and error must be done and printing checks were made for both exception and county pages. To describe further, each button at the end of each page was used to retrieve a detailed more detailed endpoint. This endpoint was the feature that is to be read in the following script.
1. Endpoint - https://www.redfin.com/county/1894/NJ/Camden-County/filter/mr=5:1898
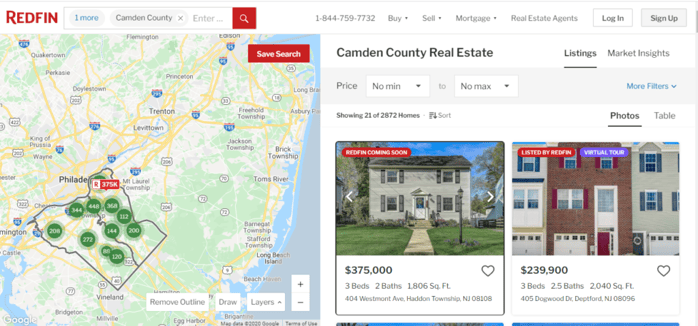
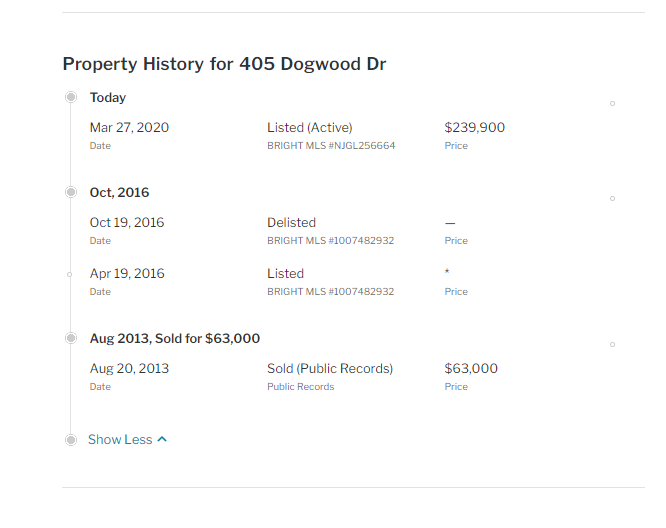
2. Endpoint - https://www.redfin.com/NJ/Deptford-Township/405-Dogwood-Dr-08096/home/105270038
Structure
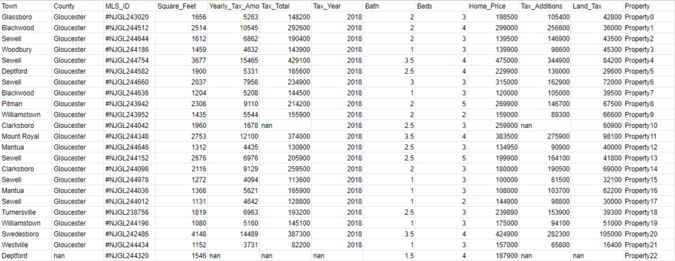
As each home's endpoint was retrieved, its main scrapping occurred through the 'detail_page.py '. The divisions on the page that were taken off the HTML are from Town, County, MLSID, Square feet, Table_Appreciation, Bath, Beds, Table_Event, Home Price, Table_Date, Land Value, Table _Source, Table_Price, Tax Year, Tax Amount, Tax Additional, and Tax Total. While these columns have been made and also cleaned of frivolous characters, each value has went through some level of a preprocessing. This cleaning has mainly taken place through regular expressions.
The structure of the file is rather simple but each predictor or independent feature can be quite cumbersome. Through each expression the files must be reran in order to see if its output removed character strings or formatted the numerical values. It is also not short of if the file is ran enough times, the bot will be flagged for security parameters.
Conclusion
Further analysis and exploration should done through this information. Prior to this, feature transformation must be done for null values and other potential bugs that may arise. This and other mapping may also be done has the exploration occurs. It is a powerful tool that if advised may revolve more or around other scrapping tools.
Github: Scrapper
Darien
Topics from this blog: python Web Scraping APIs Data Science News and Sharing